This page provides a deeper dive into how fleets help you manage multi-cluster deployments, including some key fleet terminology and concepts. Fleets are a Google Cloud concept for logically organizing clusters and other resources, letting you use and manage multi-cluster capabilities and apply consistent policies across your systems. Fleets form a crucial part of how enterprise multi-cluster functionality works in Google Cloud.
This guide is designed for technical readers, including system architects, platform operators, and service operators, who want to leverage multiple clusters and related infrastructure. These concepts are useful wherever your organization happens to be running multiple clusters, whether in Google Cloud, across multiple cloud providers, or on-premises.
Before reading this page, ensure that you're familiar with basic Kubernetes concepts such as clusters and namespaces; if you're not, see Kubernetes basics, the GKE documentation, and Preparing an application for Cloud Service Mesh.
If you want to learn more about the GKE Enterprise platform and the components that use fleets, see our GKE Enterprise technical overview and Explore GKE Enterprise tutorial. However, you don't need to be familiar with GKE Enterprise to follow this guide.
Terminology
The following are some important terms we use when talking about fleets.
Fleet-aware resources
Fleet-aware resources are Google Cloud project resources that can be logically grouped and managed as fleets. Only Kubernetes clusters can currently be fleet members.
Fleet host project
The implementation of fleets, like many other Google Cloud resources, is rooted in a Google Cloud project, which we refer to as the fleet host project. A given Google Cloud project can only have a single fleet (or no fleets) associated with it. This restriction reinforces using Google Cloud projects to provide stronger isolation between resources that are not governed or consumed together.
Grouping infrastructure
The first important concept of fleets is the concept of grouping—that is, choosing which pieces of related fleet-aware resources should be made part of a fleet. The decision about what to group together requires answering the following questions:
- Are the resources related to one another?
- Resources that have large amounts of cross-service communication benefit the most from being managed together in a fleet.
- Resources in the same deployment environment (for example, your production environment) should be managed together in a fleet.
- Who administers the resources?
- Having unified (or at least mutually trusted) control over the resources is crucial to ensuring the integrity of the fleet.
To illustrate this point, consider an organization that has multiple lines of business (LOBs). In this case, services rarely communicate across LOB boundaries, services in different LOBs are managed differently (for example, upgrade cycles differ between LOBs), and they might even have a different set of administrators for each LOB. In this case, it might make sense to have fleets per LOB. Each LOB also likely adopts multiple fleets to separate their production and non-production services.
As other fleet concepts are explored in the following sections, you might find other reasons to create multiple fleets as you consider your specific organizational needs.
Sameness
An important concept in fleets is the concept of sameness. This means that when you use certain fleet-enabled features, some Kubernetes objects such as namespaces that have the same name in different clusters are treated as if they were the same thing. This normalization is done to make administering fleet resources easier. If you're using features that leverage sameness, this assumption of sameness provides some strong guidance about how to set up namespaces, services, and identities. However, it also follows what we find most organizations already implementing themselves.
Different types of sameness provide different benefits, as shown in the following table:
| Sameness property | Lets you... |
|---|---|
| A namespace is considered the same across multiple clusters. |
|
| A combination of namespace and service name is considered the same across multiple clusters. Same-named services in the same namespace use the same label selector. |
|
| A combination of namespace and service account (identity) is considered the same across multiple clusters. |
|
As this suggests, different fleet features rely on different types of sameness. A smaller number of features don't use sameness at all. You can learn more about this in Which features use sameness?, including which features you can use without having to consider fleet-wide sameness and which features may require more careful planning.
Namespace sameness
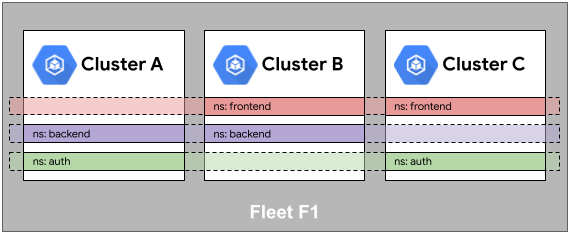
The fundamental example of sameness in a fleet is namespace sameness. Namespaces with the same name in different clusters are considered the same by many fleet features. Another way to think about this property is that a namespace is logically defined across an entire fleet, even if the instantiation of the namespace exists only in a subset of the fleet resources.
Consider the following backend namespace example. Although the namespace is
instantiated only in Clusters A and B, it is implicitly reserved in Cluster C
(it allows a service in the backend namespace to also be scheduled into Cluster C if necessary).
This means that namespaces are allocated for the entire fleet and not per
cluster. As such, namespace sameness requires consistent namespace ownership
across the fleet.
Service sameness
Cloud Service Mesh and Multi Cluster Ingress use the concept of sameness of services within a namespace. Like namespace sameness, this implies that services with the same namespace and service name are considered to be the same service.
The service endpoints can be merged across the mesh in the case of Cloud Service Mesh. With Multi Cluster Ingress, a MultiClusterService (MCS) resource makes the endpoint merging more explicit; however, we recommend similar practices with respect to naming. Because of this, it's important to ensure that identically named services within the same namespace are actually the same thing.
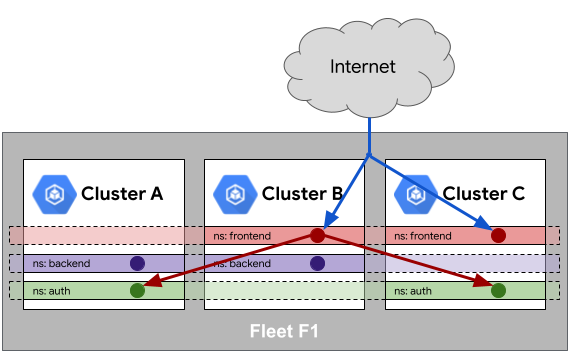
In the following example, internet traffic is load balanced across a same-named
service in the frontend namespace present in both Clusters B and C. Similarly,
using the service mesh properties within the fleet, the service in the frontend namespace can
reach a same-named service in the auth namespace present in Clusters A and C.
Identity sameness when accessing external resources
With fleet Workload Identity Federation, services within a fleet can leverage a common identity as they egress to access external resources such as Google Cloud services, object stores, and so on. This common identity makes it possible to give the services within a fleet access to an external resource once rather than cluster-by-cluster.
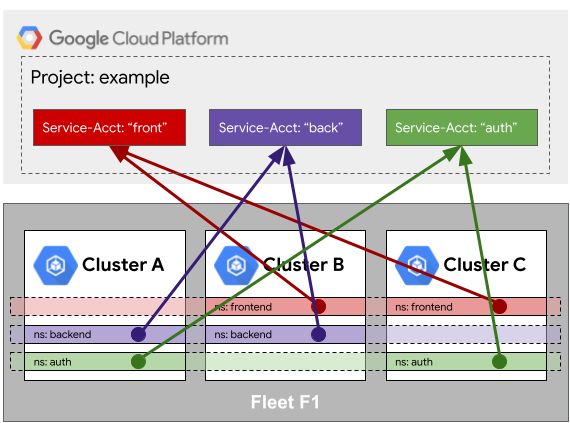
To illustrate this point further, consider the following example. Clusters A, B,
and C are enrolled in common identity within their fleet. When services in the
backend namespace access Google Cloud resources, their identities are
mapped to a common Google Cloud service account called back. The
Google Cloud service account back can be authorized on any number of
managed services, from Cloud Storage to Cloud SQL. As new fleet resources
such as clusters are added in the backend namespace, they automatically
inherit the workload identity sameness properties.
Because of identity sameness, it is important that all resources in a fleet
are trusted and well-governed. Revisiting the previous example, if Cluster C is
owned by a separate, untrusted team, they too can create a backend namespace
and access managed services as if they were the backend in Cluster A
or B.
Identity sameness within a fleet
Within the fleet, identity sameness is used similarly to the external identity sameness we previously discussed. Just as fleet services are authorized once for an external service, they can be authorized internally as well.
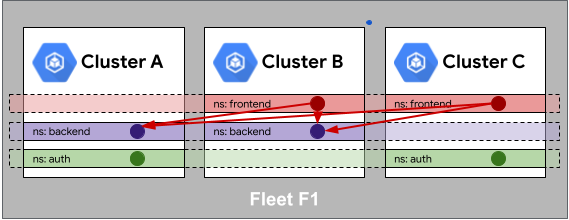
In the following example, we are using Cloud Service Mesh
to create a multi-cluster service mesh where frontend has access to backend.
With Cloud Service Mesh and
fleets, we don't need to specify that frontend in clusters B and C can
access backend in Clusters A and B. Instead, we just specify that frontend
in the fleet can access backend in the fleet. This property not only makes
authorization simpler, it also makes the resource boundaries more flexible; now
workloads can easily be moved from cluster to cluster without affecting how they
are authorized. As with workload identity sameness, governance over the fleet
resources is crucial to ensuring the integrity of service-to-service
communication.
Which features use sameness?
A number of fleet features don't rely on sameness at all, and can be enabled and used without having to consider whether you want to assume any form of sameness across your fleet. Other features (including Config Sync and Policy Controller) can use sameness - for example, if you want to select a namespace across multiple fleet member clusters for configuration from a single source of truth - but do not require it for all use cases. Finally, there are features such as Multi Cluster Ingress and fleet-wide Workload Identity Federation that always assume some form of sameness across clusters, and may have to be adopted with care depending on your needs and existing workloads.
Some fleet features (such as fleet Workload Identity Federation) require that your entire fleet is ready for the assumptions of sameness that they use. Other features such as team management let you gradually opt in to sameness at the namespace or team scope level.
The following table shows which features require one or more of the sameness concepts described in this section.
| Feature | Supports gradual sameness adoption | Depends on namespace sameness | Depends on service sameness | Depends on identity sameness |
|---|---|---|---|---|
| Fleets | N/A | No | No | No |
| Binary Authorization | N/A | No | No | No |
| Inter-node transparent encryption | N/A | No | No | No |
| Fully Qualified Domain Name-based Network Policy | N/A | No | No | No |
| Connect gateway | N/A | No | No | No |
| Config Sync | N/A | No | No | No |
| Policy Controller | N/A | No | No | No |
| GKE Security Posture | N/A | No | No | No |
| Advanced Vulnerability Insights | N/A | No | No | No |
| Compliance Posture | N/A | No | No | No |
| Rollout sequencing | N/A | No | No | No |
| Team management | Yes | Yes | Yes | No |
| Multi Cluster Ingress | Yes | Yes | Yes | Yes |
| Multi Cluster Services | Yes | Yes | Yes | Yes |
| Fleet Workload Identity Federation | No | Yes | Yes | Yes |
| Cloud Service Mesh | No | Yes | Yes | Yes |
Exclusivity
Fleet-aware resources can only be members of a single fleet at any given time, a restriction that is enforced by Google Cloud tools and components. This restriction ensures that there is only one source of truth governing a cluster. Without exclusivity, even the most simple components would become complex to use, requiring your organization to reason about and configure how multiple components from multiple fleets would interact.
High trust
Service sameness, workload identity sameness, and mesh identity sameness are built on top of a principle of high trust between members of a fleet. This trust makes it possible to uplevel management of these resources to the fleet, rather than managing resource-by-resource (that is, cluster-by-cluster for Kubernetes resources), and ultimately makes the cluster boundary less important.
Put another way, within a fleet, clusters provide protection from blast radius concerns, availability (of both the control plane and underlying infrastructure), noisy neighbors, and so on. However, they are not a strong isolation boundary for policy and governance because administrators of any member in a fleet can potentially affect the operations of services in other members of the fleet.
For this reason, we recommend that clusters that are not trusted by the fleet administrator be placed in their own fleets to keep them isolated. Then, as necessary, individual services can be authorized across the fleet boundary.
Team scopes
A team scope is a mechanism for further subdividing your fleet into groups of clusters, letting you define the fleet-aware resources assigned to a specific application team. Depending on your use case, an individual fleet member cluster can be associated with no teams, one team, or multiple teams, allowing multiple teams to share clusters. You can also use team scopes to sequence cluster upgrade rollouts across your fleet, although this requires that each cluster is only associated with a single team.
A team scope can have explicitly defined fleet namespaces associated with it, where the namespace is considered the same across the scope. This gives you more granular control over namespaces than the default namespace sameness provided by fleets alone.
Fleet-enabled components
The following GKE Enterprise and GKE components all leverage fleet concepts such as namespace and identity sameness to provide a simplified way to work with your clusters and services. For any current requirements or limitations for using fleets with each component, see the component requirements.
Workload identity pools
A fleet offers a common workload identity pool that can be used to authenticate and authorize workloads uniformly within a service mesh and to external services.Cloud Service Mesh
Cloud Service Mesh is a suite of tools that helps you monitor and manage a reliable service mesh on Google Cloud, on-premises, and other supported environments. You can form a service mesh across clusters that are part of the same fleet.Config Sync
Config Sync lets you deploy and monitor declarative configuration packages for your system stored in a central source of truth, like a Git repository, leveraging core Kubernetes concepts such as namespaces, labels, and annotations. With Config Sync, configuration are defined across the fleet, but applied and enforced locally in each of the member resources.Policy Controller
Policy Controller lets you apply and enforce declarative policies for your Kubernetes clusters. These policies act as guardrails and can help with best practices, security, and compliance management of your clusters and fleet.Multi Cluster Ingress
Multi Cluster Ingress uses the fleet to define the set of clusters and service endpoints that traffic can be load balanced over, enabling low-latency and high-availability services.
What's next?
- Read more about when to use multiple clusters to meet your technical and business needs in Multi-cluster use cases.
- Ready to think about applying these concepts to your own systems? See Plan fleet resources.