Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
This tutorial shows how to use Cloud Composer to create an Apache Airflow DAG (Directed Acyclic Graph) that runs an Apache Hadoop wordcount job on a Dataproc cluster.
Objectives
- Access your Cloud Composer environment and use the Airflow UI.
- Create and view Airflow environment variables.
- Create and run a DAG that includes the following tasks:
- Creates a Dataproc cluster.
- Runs an Apache Hadoop word-count job on the cluster.
- Outputs the word-count results to a Cloud Storage bucket.
- Deletes the cluster.
Costs
In this document, you use the following billable components of Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
Make sure that the following APIs are enabled in your project:
Console
Enable the Dataproc, Cloud Storage APIs.
gcloud
Enable the Dataproc, Cloud Storage APIs:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com In your project, create a Cloud Storage bucket of any storage class and region to store the results of the Hadoop word-count job.
Note the path of the bucket that you created, for example
gs://example-bucket. You'll define an Airflow variable for this path and use the variable in the example DAG later in this tutorial.Create a Cloud Composer environment with default parameters. Wait until environment creation is completed. When done, the green check mark displays to the left of the environment name.
Note the region where you created your environment, for example
us-central. You'll define an Airflow variable for this region and use it in the example DAG to run a Dataproc cluster in the same region.
Set Airflow variables
Set the Airflow variables to use later in the example DAG. For example, you can set Airflow variables in the Airflow UI.
| Airflow variable | Value |
|---|---|
gcp_project
|
The project ID of the project
you're using for this tutorial, such as example-project. |
gcs_bucket
|
The URI Cloud Storage bucket you created for this tutorial,
such as gs://example-bucket |
gce_region
|
The region where you created your environment, such as us-central1.
This is the region where your Dataproc cluster
will be created. |
View the example workflow
An Airflow DAG is a collection of organized tasks that you want to schedule
and run. DAGs are defined in standard Python files. The code shown in
hadoop_tutorial.py is the workflow code.
Operators
To orchestrate the three tasks in the example workflow, the DAG imports the following three Airflow operators:
DataprocClusterCreateOperator: Creates a Dataproc cluster.DataProcHadoopOperator: Submits a Hadoop wordcount job and writes results to a Cloud Storage bucket.DataprocClusterDeleteOperator: Deletes the cluster to avoid incurring ongoing Compute Engine charges.
Dependencies
You organize tasks that you want to run in a way that reflects their relationships and dependencies. The tasks in this DAG run sequentially.
Scheduling
The name of the DAG is composer_hadoop_tutorial, and the DAG runs once each
day. Because the start_date that is passed in to default_dag_args is
set to yesterday, Cloud Composer schedules the workflow
to start immediately after the DAG is uploaded to the environment's bucket.
Upload the DAG to the environment's bucket
Cloud Composer stores DAGs in the /dags folder in your
environment's bucket.
To upload the DAG:
On your local machine, save
hadoop_tutorial.py.In the Google Cloud console, go to the Environments page.
In the list of environments, in the DAGs folder column for your environment, click the DAGs link.
Click Upload files.
Select
hadoop_tutorial.pyon your local machine and click Open.
Cloud Composer adds the DAG to Airflow and schedules the DAG automatically. DAG changes occur within 3-5 minutes.
Explore DAG runs
View task status
When you upload your DAG file to the dags/ folder in Cloud Storage,
Cloud Composer parses the file. When completed successfully, the name
of the workflow appears in the DAG listing, and the workflow is queued to run
immediately.
To see task status, go to the Airflow web interface and click DAGs in the toolbar.
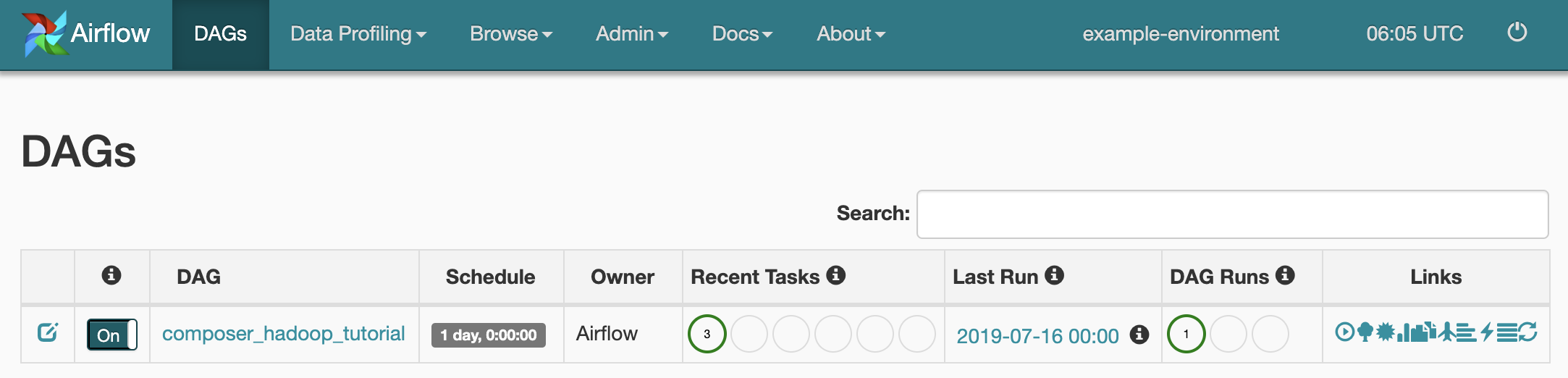
To open the DAG details page, click
composer_hadoop_tutorial. This page includes a graphical representation of workflow tasks and dependencies.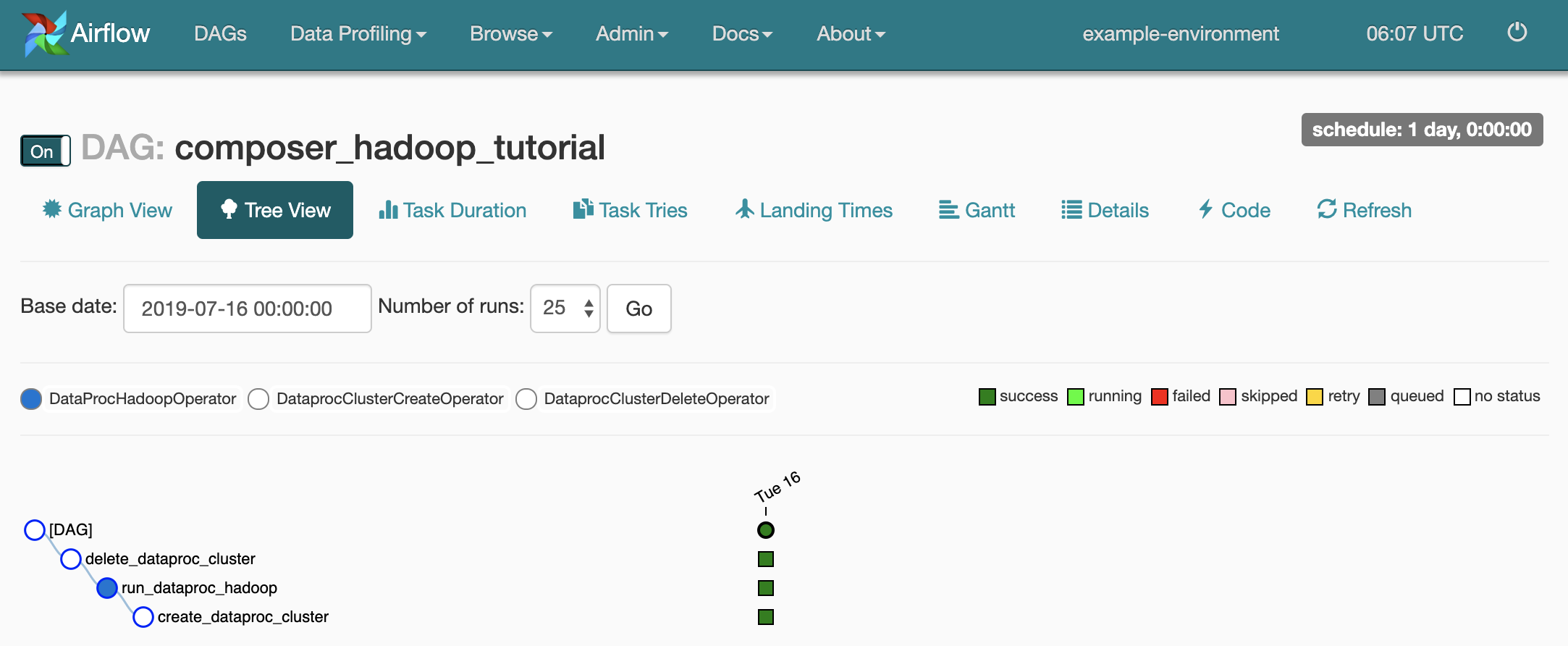
To see each task's status, click Graph View and then mouseover the graphic for each task.
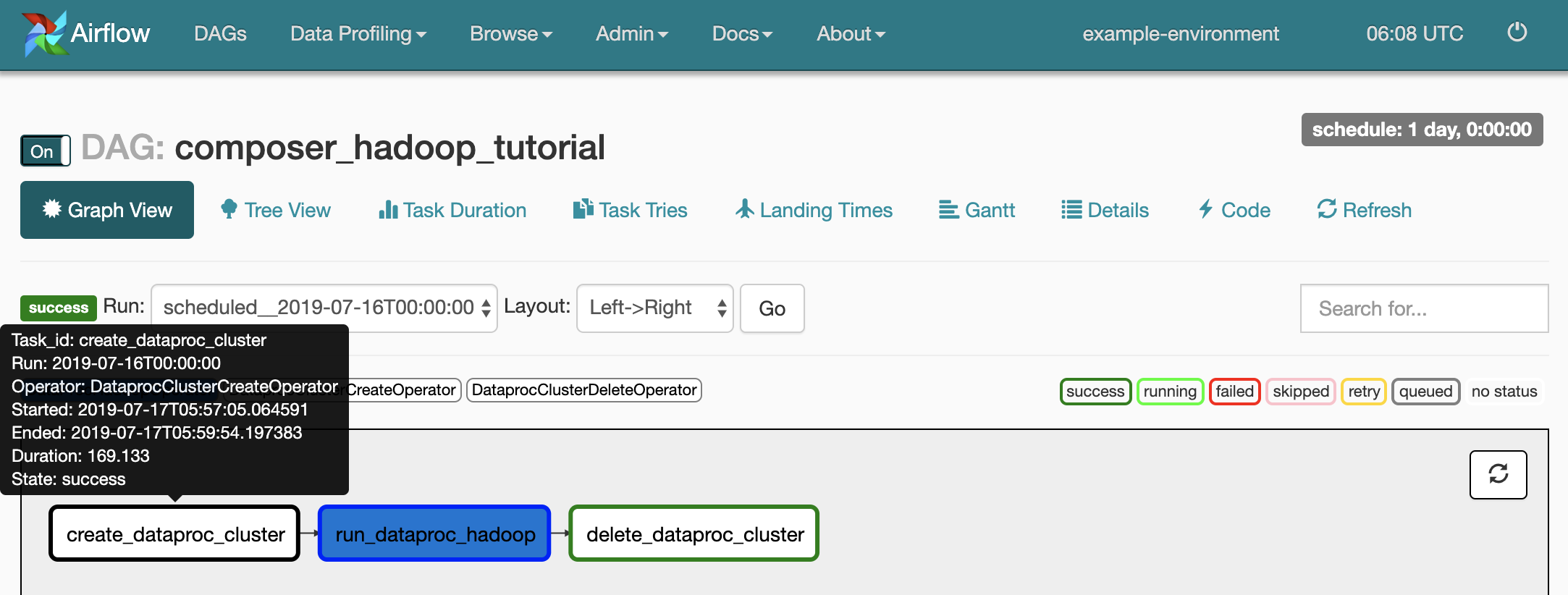
Queue the workflow again
To run the workflow again from the Graph View:
- In the Airflow UI Graph View, click the
create_dataproc_clustergraphic. - To reset the three tasks, click Clear and then click OK to confirm.
- Click
create_dataproc_clusteragain in Graph View. - To queue the workflow again, click Run.
View task results
You can also check the status and results of the composer_hadoop_tutorial
workflow by going to the following Google Cloud console pages:
Dataproc Clusters: to monitor cluster creation and deletion. Note that the cluster created by the workflow is ephemeral: it only exists for the duration of the workflow and is deleted as part of the last workflow task.
Dataproc Jobs: to view or monitor the Apache Hadoop wordcount job. Click the Job ID to see job log output.
Cloud Storage Browser: to see the results of the wordcount in the
wordcountfolder in the Cloud Storage bucket you created for this tutorial.
Cleanup
Delete the resources used in this tutorial:
Delete the Cloud Composer environment, including manually deleting the environment's bucket.
Delete the Cloud Storage bucket that stores the results of the Hadoop word-count job.