This document helps you to migrate your Apache Kafka workloads to Google Cloud Managed Service for Apache Kafka which is a managed service within Google Cloud.
Managed Service for Apache Kafka helps you run Apache Kafka on Google Cloud. In this documented solution, you move data from an external Apache Kafka cluster into a Managed Service for Apache Kafka cluster.
For more information about Managed Service for Apache Kafka, see Managed Service for Apache Kafka overview.
We recommend that you use Apache Kafka MirrorMaker 2.0 for this migration.
MirrorMaker 2.0 is a tool for replicating data between Apache Kafka clusters in real time. It can be used for data migrations, disaster recovery, data isolation, and data aggregation.
For more information about MirrorMaker 2.0, see the next section.
What is MirrorMaker 2.0
MirrorMaker 2.0 uses the Kafka Connect framework to replicate data between Kafka clusters. Kafka Connect is a framework for streaming data between Kafka clusters and other systems. It acts as a scalable and reliable pipeline. This framework simplifies the integration of Kafka with various external systems, such as databases, message queues, and online storage, through the use of readily available connectors. The following is a list of possible scenarios where you can use MirrorMaker 2.0:
Data migrations: Move your Kafka workload to a new cluster, as demonstrated in this guide.
Disaster recovery: Create a backup cluster to ensure business continuity in case of failures.
Data isolation: Selectively replicate topics to a public cluster while keeping sensitive data secure in a private cluster.
Data aggregation: Consolidate data from multiple Kafka clusters into a central cluster for analytical purposes.
MirrorMaker 2.0 supports Kafka version 2.4.0 and higher, offering these key features:
Comprehensive replication: Replicates all necessary components, including topics, data, and configurations, consumer groups with offsets, and ACLs.
Partition preservation: Maintains the same partitioning scheme in the target cluster, simplifying the transition for applications.
Automatic topic and partition creation: Automatically detects and replicates new topics and partitions, minimizing manual configuration.
Monitoring capabilities: Provides essential metrics like end-to-end replication latency, letting you track the health and performance of the replication process.
Fault tolerance and scalability: Ensures reliable operation even with high data volumes and can be scaled horizontally to handle increasing workloads.
Internal topics for robustness: Utilizes internal topics for offset synchronization, checkpoints, and heartbeats. These topics have configurable replication factors such as
offset.syncs.topic.replication.factorto ensure high availability and fault tolerance.
MirrorMaker 2.0 offers two deployment modes:
Dedicated cluster mode: MirrorMaker 2.0 runs as a standalone cluster, managing its own workers. This document focuses on this mode, providing a practical example of its deployment and configuration.
Kafka Connect cluster mode: MirrorMaker 2.0 runs as connectors within an existing Kafka Connect cluster.
High-level workflow
This following diagram illustrates the architecture for migrating data from a source Apache Kafka cluster to a Managed Service for Apache Kafka cluster using MirrorMaker 2.0.
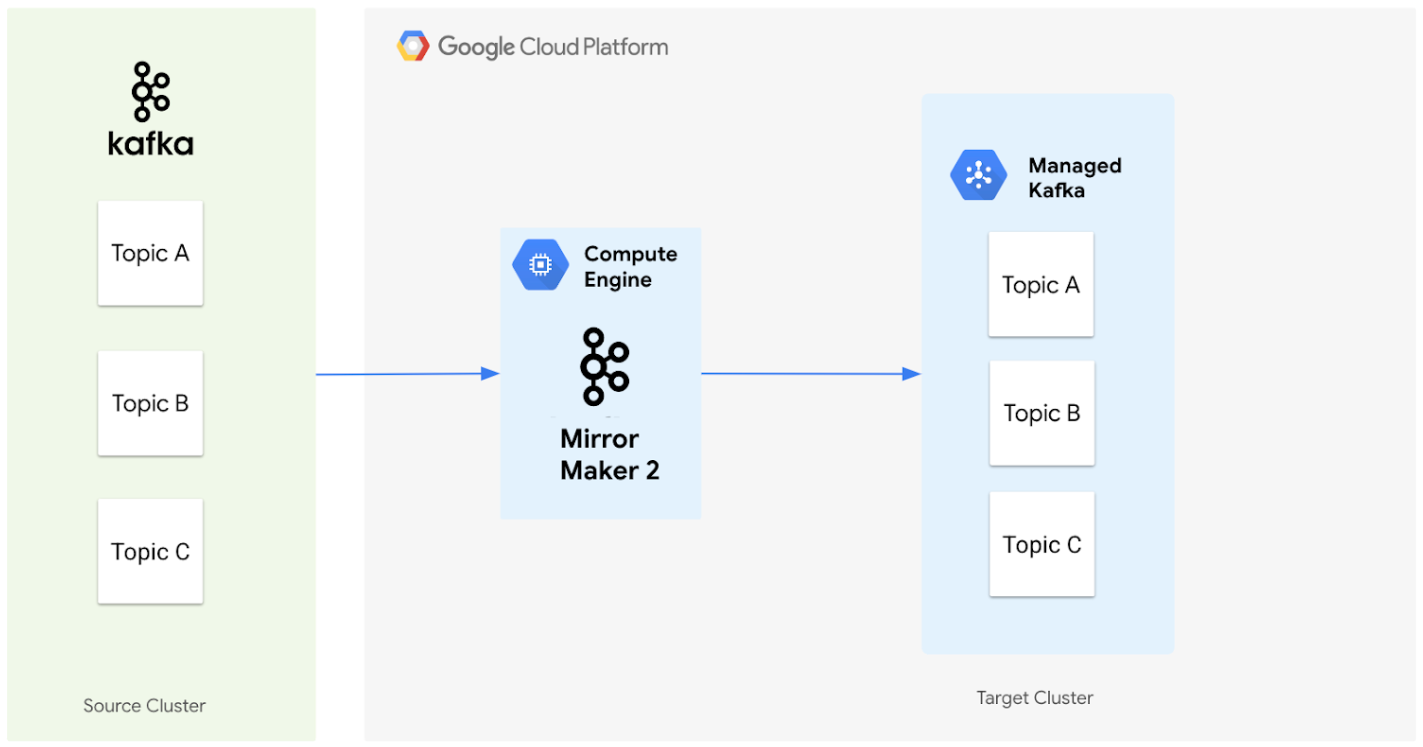
Here's how the components work together:
Source cluster: This represents your existing Apache Kafka cluster, which can be located on-premises or in another cloud environment. It contains the topics that you want to migrate. In this diagram, the source Apache Kafka cluster contains three topics which are Topic A, B, and C.
MirrorMaker 2.0: This core component, deployed on a Compute Engine VM as a dedicated MirrorMaker 2.0 cluster, actively replicates data from the source Apache Kafka cluster to the target Managed Service for Apache Kafka cluster. Importantly, it also automatically creates the corresponding topics and partitions in the target cluster if they don't exist, mirroring the source cluster setup.
Target cluster: This is your Managed Service for Apache Kafka cluster. It becomes the new home for your Kafka data, with MirrorMaker 2.0 ensuring that the topics and partitions are created to match your source environment.
Here is a high-level workflow for the migration process.
Initial assessment
Document your existing Kafka setup including cluster size, topics, throughput, and consumer groups.
Plan your migration goals and strategy including downtime tolerance and cutover approach.
Estimate the resources required for your Managed Service for Apache Kafka cluster.
Preparation
Create a Managed Service for Apache Kafka cluster.
Configure network connectivity between your existing Kafka cluster and the Managed Service for Apache Kafka cluster that you just created.
Deploy MirrorMaker 2.0 on a Google Cloud VM.
Migration execution
Configure MirrorMaker 2.0 to replicate data from your existing Kafka cluster to the Managed Service for Apache Kafka cluster.
Monitor the replication process using MirrorMaker 2.0 metrics.
Gradually migrate the consumers and producers to the new Managed Service for Apache Kafka cluster.
Validation and cutover
Validate data integrity and application features in the Managed Service for Apache Kafka cluster.
Perform the final cutover, redirecting traffic to Managed Service for Apache Kafka cluster.
Decommission your old Kafka cluster.
Post-migration
Continuously monitor the performance of your Managed Service for Apache Kafka cluster.
Review and update documentation to reflect the changes.
Minimize the migration downtime
This section outlines some considerations for migrating your open source Kafka data to Managed Service for Apache Kafka using MirrorMaker 2.0. MirrorMaker 2.0 does facilitate data and offset replication that lets consumers resume from the correct point in the new cluster. However, careful planning is crucial to minimize the downtime during the migration process. Consider these strategies:
Parallel deployments: To minimize downtime when switching to the new Managed Service for Apache Kafka cluster, you can run parallel instances of your applications on both the old and new clusters. During this transition, temporarily disable any actions in your application that must happen only once per message, such as sending a notification. Disable these side effects to prevent unintended consequences from processing the same message twice. After the new instances are fully caught up, redirect all traffic to the new cluster and re-enable all features.
Phased rollouts: Migrate in smaller, manageable phases, starting with less critical applications. This approach helps isolate potential issues and minimizes the impact of any disruptions.
Blue and green deployments: Create a complete replica of your production environment (green) alongside the existing one (blue). Gradually shift traffic from blue to green, allowing for testing and validation before the final cutover. This approach minimizes downtime but requires increased resource utilization.
Message processing requirements: Understand your application's tolerance for duplicate or missing messages and configure consumers accordingly. MirrorMaker 2.0 offers configurations to handle message delivery semantics. For example,
sync.group.offsets.enabledsupports consumer offset sync. Consumers can use the synced offsets to resume reading from where they had left off at the source cluster. Doing so can prevent message loss or prevent receiving too many duplicates.Communication and coordination: Effective communication with application teams is essential for a smooth migration. Establish clear communication channels and coordinate switchover timings.
Connect on-premises Apache Kafka to Google Cloud
If your source Apache Kafka cluster is located on-premises, you'll need to establish a secure connection between your on-premises network and your Virtual Private Cloud (VPC) where your Managed Service for Apache Kafka cluster resides. Use one of the following options from Google Cloud.
Cloud VPN: A cost-effective solution suitable for lower bandwidth needs or initial migration experiments. It creates an encrypted tunnel over the public internet. For more information about Cloud VPN, see Cloud VPN overview.
Cloud Interconnect: Provides a dedicated, high-bandwidth connection between your on-premises network and Google Cloud. This is ideal for enterprise-grade deployments requiring higher throughput and lower latency. You can choose between Dedicated Interconnect (for direct physical connection) or Partner Interconnect (connection through a supported service provider). For more information about Google Cloud Interconnect documentation, see Cloud Interconnect overview.
When you create a Managed Service for Apache Kafka cluster, you must select at least one subnet in your VPC. This subnet provides the IP addresses that your cluster uses to communicate with other resources in your VPC, making the cluster accessible within your VPC network.
To securely connect to your Managed Service for Apache Kafka cluster from on-premises networks or other VPC networks, you can use Private Service Connect (PSC) over Cloud VPN or Cloud Interconnect. You don't need to explicitly set up PSC endpoints. When you select a subnet during cluster creation, the Managed Service for Apache Kafka service automatically creates the necessary PSC endpoints. This simplifies network configuration by allowing you to access your cluster using internal IP addresses within your VPC, without needing to manage complex firewall rules or public IP addresses.
For more information about the networking setup for Managed Service for Apache Kafka, see Networking for Managed Service for Apache Kafka.
Before you begin
Before you begin with creating the migration setup, you must document your current Apache Kafka setup. You need this so that you can calculate the resources, such as vCPUs, memory, and storage, required for your new Managed Service for Apache Kafka cluster. Gather the following information about your source Apache Kafka environment:
Ensure that the Apache Kafka version is 2.4.0 or higher.
To check the version of your Apache Kafka cluster, navigate to your Kafka installation directory and run the command
bin/kafka-topics.sh --versionIdentify the clusters and topics that need to be migrated.
Identify the producers and consumers associated with each topic.
Identify all consumer groups.
Determine the message throughput at both the cluster and topic level.
Determine the replication factor for your clusters and topics.
Document consumer configurations, especially security protocols and any integration with other Google Cloud services.
To avoid disruptions during the migration, map out all application dependencies related to your source Kafka cluster. Before migrating your production environment, conduct a test migration using a non-critical cluster in a development environment. Validate the process and identify any potential issues. Finally, create a comprehensive rollback plan to revert to your original cluster if necessary.
Calculate the destination cluster size
To estimate the number of vCPUs and size of memory required for your Managed Service for Apache Kafka cluster, see Estimate vCPUs and memory for your cluster. Disk and broker configuration are automatic and cannot be adjusted.
Open-source Kafka provides JMX metrics. To accurately calculate the required cluster size for your Managed Service for Apache Kafka, you can use the following JMX metrics. These metrics are reported at the broker level. You must aggregate the data across all brokers to calculate the cluster throughput.
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: This metric reports the incoming byte rate from clients across all topics. Omit thetopic={...}parameter to get the aggregate rate for all topics.kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: This metric reports the outgoing byte rate to clients across all topics. Omit thetopic={...}parameter to obtain the overall rate.
By monitoring these JMX metrics over a period of time, you can gather data points to calculate the following:
Average Data In, MB/s: This metric represents the average rate at which data is being ingested into the Kafka cluster.
Peak Data In, MB/s: This metric represents the highest rate at which data is being ingested into the Kafka cluster.
Average Data Out, MB/s: This metric represents the average rate at which data is being consumed from the Kafka cluster.
Peak Data Out, MB/s: This metric represents the highest rate at which data is being consumed from the Kafka cluster.
Some metric math might be necessary to aggregate the data and convert bytes to MB. Using these calculated values, you can then estimate the write-equivalent rate as follows:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
This write-equivalent rate helps determine the overall write load on the cluster, which is required for sizing your Managed Service for Apache Kafka cluster appropriately.
Create a Managed Service for Apache Kafka cluster
A Managed Service for Apache Kafka cluster is located in a specific Google Cloud project and region. It can be accessed using a set of IP addresses within one or more subnets in any Virtual Private Cloud (VPC).
The cluster's size is determined by the number of CPUs and total RAM that you allocate to it. In this case, the cluster size must mirror the size of the source Apache Kafka cluster. For more information about how to perform this calculation, see Calculate the destination cluster size.
To get the permissions that you need to create a cluster, ask your administrator
to grant you or the service account creating the cluster, the
Managed Kafka Admin
(roles/managedkafka.admin) IAM role on your project. For more
information about granting roles, see
Manage access to projects, folders, and organizations.
To create a Managed Service for Apache Kafka cluster, follow the quickstart instructions at Publish and consume messages with the CLI. Creating a cluster usually takes 20-30 minutes.
Set up MirrorMaker 2.0 in standalone cluster mode
For a proof of concept document and sample code that shows how to use MirrorMaker 2.0 and Terraform to transfer Kafka data to Google Cloud, see this GitHub repository.
This section guides you through installing and configuring MirrorMaker 2.0 in a standalone cluster mode on a Google Cloud VM. This setup lets you replicate data from your existing Apache Kafka cluster to a Managed Service for Apache Kafka cluster.
Create a VM in the same network that was granted access to the Managed Service for Apache Kafka cluster. Use the gcloud compute instances create command.
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
Replace the following:
VM_NAME: the name of the VM you want to create.ZONE: the zone where you want to create the VM.IMAGEorIMAGE_FAMILY: the image or image family you want to use for the VM.IMAGE_PROJECT: the project where the image is located.MACHINE_TYPE: the machine type you want to use for the VM.
To access your newly created VM, you can use SSH.
For more information about SSH connections, see About SSH connections.
To download Kafka and then to extract it, in your terminal window of the new VM, run the following commands:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzDownload Java, extract the package, and then set the Java path.
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/Edit the
path/to/kafka/config/mm2.propertiesfile and update the following properties:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10Replace
source_kafka_bootstrap_serversandtarget_kafka_bootstrap_serverswith the bootstrap server addresses of your source and target Kafka clusters, respectively. You can get the bootstrap server address for Managed Service for Apache Kafka using themanaged-kafka clusters describeGoogle Cloud CLI command.Replace
source_kafka_usernameandsource_kafka_passwordwith the credentials for your source Kafka cluster.Replace
target_kafka_usernameandtarget_kafka_passwordwith the credentials for your target Managed Service for Apache Kafka cluster. To configure the username and password, see SASL/PLAIN authentication.The
topics = .\*andgroups = .\*settings replicate all topics and consumer groups. You can modify these settings to be more specific, if needed.The
offset.syncs.topic.replication.factor = 3setting sets the replication factor for the internal topic used by MirrorMaker 2.0 to synchronize consumer offsets between the source and target clusters. A replication factor of3means that the offset data is replicated to three brokers in the target cluster, ensuring higher availability and fault tolerance.The
checkpoints.topic.replication.factor = 3setting sets the replication factor for another internal topic used by MirrorMaker 2.0 to store checkpoints. Checkpoints help MirrorMaker 2.0 track its progress and resume replication from the correct point in case of failures or restarts.The
heartbeats.topic.replication.factor = 3setting sets the replication factor for the internal topic used by MirrorMaker 2.0 to send heartbeats. Heartbeats signal that the MirrorMaker 2.0 process is alive and active. A higher replication factor ensures that these heartbeats are reliably stored and can be used to monitor the health of the replication process.The
emit.checkpoints.interval.seconds = 10setting controls how frequently MirrorMaker 2.0 emits checkpoints. In this case, checkpoints are emitted every 10 seconds. This frequency provides a balance between tracking progress and minimizing the overhead of writing checkpoints.
Start MirrorMaker 2.0. Use the
connect-mirror-maker.shscript to start the process.The script starts MirrorMaker 2.0 in standalone mode, and it begins replicating data from your source Kafka cluster to your Managed Service for Apache Kafka cluster.
Additional considerations:
Networking: Ensure that your Google Cloud VM has network connectivity to both your source Kafka cluster and your target Managed Service for Apache Kafka cluster. If your source cluster is on-premises, you might need to configure VPN or Interconnect.
Security: Configure appropriate security protocols and firewall rules to secure your MirrorMaker 2.0 instance and your Kafka clusters.
By following these steps, you can successfully install and configure MirrorMaker 2.0 in standalone cluster mode on a Google Cloud VM to facilitate your Kafka data migration to Managed Service for Apache Kafka.
Monitoring
Monitor the MirrorMaker 2.0 process to ensure it's running correctly and replicating data as expected. You can use MirrorMaker 2's built-in metrics or other monitoring tools. After migrating your applications, monitor the following to validate success:
Downstream throughput rates: Ensure no significant changes in downstream throughput rates. For example, if you're using Dataflow downstream, the throughput and metrics related to Kafka must remain consistent.
CPU and memory utilization: Monitor the CPU and memory utilization of your Managed Service for Apache Kafka cluster using Cloud Monitoring. Utilization must ideally remain less than 75% to ensure optimal performance.
Error logs: Regularly check Cloud Logging for any error logs related to your Managed Service for Apache Kafka cluster or your applications. Address any errors promptly to prevent disruptions.
Limitations
- MirrorMaker 2.0 requires your source Apache Kafka cluster to be version 2.4.0 or higher.