The job builder is a visual UI for building and running Dataflow pipelines in the Google Cloud console, without writing code.
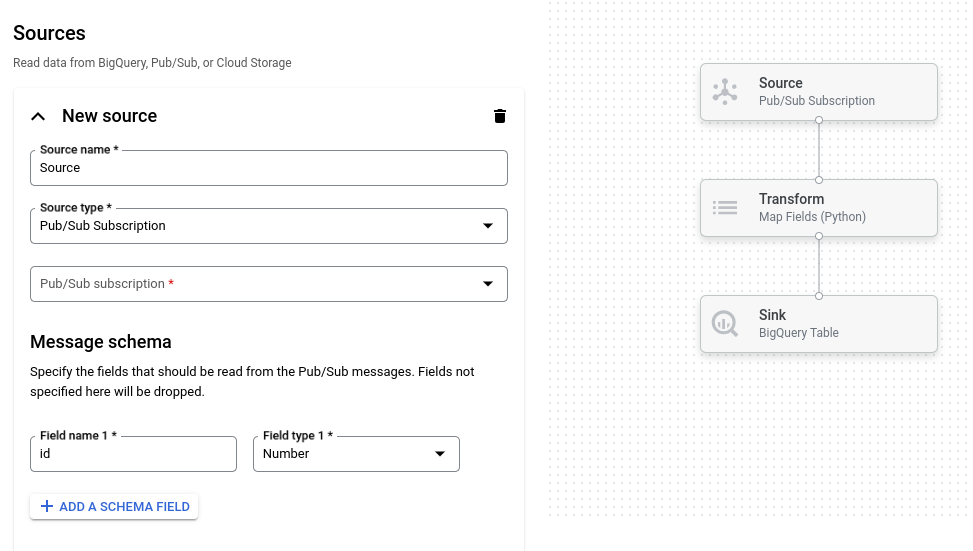
The following image shows a detail from the job builder UI. In this image, the user is creating a pipeline to read from Pub/Sub to BigQuery:
Overview
The job builder supports reading and writing the following types of data:
- Pub/Sub messages
- BigQuery table data
- CSV files, JSON files, and text files in Cloud Storage
It supports pipeline transforms including filter, join, map, group-by, and explode (array flatten).
The job builder can also save pipelines as Apache Beam YAML files. By using this feature, you can design your pipeline in the job builder and then store the YAML file in Cloud Storage or a source control repository for reuse.
Consider the job builder for the following use cases:
- You want to build a pipeline quickly without writing code.
- You want to save a pipeline to YAML for re-use.
- Your pipeline can be expressed using the supported sources, sinks, and transforms.
- There is no Google-provided template that matches your use case.
Create a new pipeline
To create a new pipeline in the job builder, follow these steps:
Go to the Jobs page in the Google Cloud console.
Click Create job from builder.
For Job name, enter a name for the job.
Select either Batch or Streaming.
If you select Streaming, select a windowing mode. Then enter a specification for the window, as follows:
- Fixed window: Enter a window size, in seconds.
- Sliding window: Enter a window size and window period, in seconds.
- Session window: Enter a session gap, in seconds.
For more information about windowing, see Windows and windowing functions.
Next, add sources, transforms, and sinks to the pipeline, as described in the following sections.
Add a source to the pipeline
A pipeline must have at least one source. Initially, the job builder is populated with an empty source. To configure the source, perform the following steps:
In the Source name box, enter a name for the source or use the default name. The name appears in the job graph when you run the job.
In the Source type list, select the type of data source.
Depending on the source type, provide additional configuration information. For example, if you select BigQuery, specify the table to read from.
If you select Pub/Sub, specify a message schema. Enter the name and data type of each field that you want to read from Pub/Sub messages. The pipeline drops any fields that aren't specified in the schema.
Optional: For some source types, you can click Preview source data to preview the source data.
To add another source to the pipeline, click Add a source. To combine data
from multiple sources, add the Join transform to your pipeline.
Add a transform to the pipeline
Optionally, add one or more transforms to the pipeline. To add a transform:
Click Add a transform.
In the Transform name box, enter a name for the transform or use the default name. The name appears in the job graph when you run the job.
In the Transform type list, select the type of transform.
Depending on the transform type, provide additional configuration information. For example, if you select Filter (Python), enter a Python expression to use as the filter.
Select the input step for the transform. The input step is the source or transform whose output provides the input for this transform.
Add a sink to the pipeline
A pipeline must have at least one sink. Initially, the job builder is populated with an empty sink. To configure the sink, perform the following steps:
In the Sink name box, enter a name for the sink or use the default name. The name appears in the job graph when you run the job.
In the Sink type list, select the type of sink.
Depending on the sink type, provide additional configuration information. For example, if you select the BigQuery sink, select the BigQuery table to write to.
Select the input step for the sink. The input step is the source or transform whose output provides the input for this transform.
To add another sink to the pipeline, click Add a sink.
Run the pipeline
To run a pipeline from the job builder, perform the following steps:
Optional: Set Dataflow job options. To expand the Dataflow options section, click the expander arrow.
Click Run job. The job builder navigates to the job graph for the submitted job. You can use the job graph to monitor the status of the job.
Save a pipeline
To save a pipeline to Beam YAML:
Click Save to open the Save YAML window.
Perform one of the following actions:
- To copy the YAML to the clipboard, click Copy.
- To save to Cloud Storage, enter a Cloud Storage path and click Save.
- To download a local file, click Download.
Load a pipeline
After you save a pipeline to Beam YAML, you can load it back into job builder. You can then use the job builder to modify or run the pipeline.
You can load Beam YAML from Cloud Storage or from text.
Load a pipeline from Cloud Storage
To load a pipeline from Cloud Storage:
- Click Load.
- Click Load from Cloud Storage.
- In the YAML file location box, enter the Cloud Storage location of the YAML file, or click Browse to select the file.
- Click Load.
Load a pipeline from text
To load a pipeline from text:
- Click Load.
- Click Load from text.
- Paste the YAML into the window.
- Click Load.
Validate the pipeline before launching
For pipelines with complex configuration, such as Python filters and SQL expressions, it can be helpful to check the pipeline configuration for syntax errors before launching. To validate the pipeline syntax, perform the following steps:
- Click Validate to open Cloud Shell and start the validation service.
- Click Start Validating.
- If an error is found during validation, a red exclamation mark appears.
- Fix any detected errors and verify the fixes by clicking Validate. If no error is found, a green checkmark appears.
What's next
- Use the Dataflow job monitoring interface.
- Learn more about Beam YAML.