Many organizations deploy cloud data warehouses to store sensitive information so that they can analyze the data for a variety of business purposes. This document describes how you can implement the Cloud Data Management Capabilities (CDMC) Key Controls Framework, managed by the Enterprise Data Management Council, in a BigQuery data warehouse.
The CDMC Key Controls Framework was published primarily for cloud service providers and technology providers. The framework describes 14 key controls that providers can implement to let their customers effectively manage and govern sensitive data in the cloud. The controls were written by the CDMC Working Group, with more than 300 professionals participating from more than 100 firms. While writing the framework, the CDMC Working Group considered many of the legal and regulatory requirements that exist.
This BigQuery and Data Catalog reference architecture was assessed and certified against the CDMC Key Controls Framework as a CDMC Certified Cloud Solution. The reference architecture uses various Google Cloud services and features as well as public libraries to implement the CDMC key controls and recommended automation. This document explains how you can implement the key controls to help protect sensitive data in a BigQuery data warehouse.
Architecture
The following Google Cloud reference architecture aligns with the CDMC Key Controls Framework Test Specifications v1.1.1. The numbers in the diagram represent the key controls that are addressed with Google Cloud services.

The reference architecture builds on the secured data warehouse blueprint, which provides an architecture that helps you protect a BigQuery data warehouse that includes sensitive information. In the preceding diagram, projects at the top of the diagram (in gray) are part of the secured data warehouse blueprint, and the data governance project (in blue) includes the services that are added to meet the CDMC Key Controls Framework requirements. To implement the CDMC Key Controls Framework, the architecture extends the Data governance project. The Data governance project provides controls such as classification, lifecycle management and data quality management. The project also provides a way to audit the architecture and report on findings.
For more information about how to implement this reference architecture, see the Google Cloud CDMC Reference Architecture on GitHub.
Overview of the CDMC Key Controls Framework
The following table summarizes the CDMC Key Controls Framework.
| # | CDMC key control | CDMC control requirement |
|---|---|---|
| 1 | Data control compliance | Cloud data management business cases are defined and governed. All data assets that contain sensitive data must be monitored for compliance with the CDMC Key Controls, using metrics and automated notifications. |
| 2 | Data ownership is established for both migrated and cloud-generated data | The Ownership field in a data catalog must be populated for all sensitive data or otherwise reported to a defined workflow. |
| 3 | Data sourcing and consumption are governed and supported by automation | A register of authoritative data sources and provisioning points must be populated for all data assets that contain sensitive data or otherwise must be reported to a defined workflow. |
| 4 | Data sovereignty and cross-border data movement are managed | The data sovereignty and cross-border movement of sensitive data must be recorded, audited, and controlled according to defined policy. |
| 5 | Data catalogs are implemented, used, and interoperable | Cataloging must be automated for all data at the point of creation or ingestion, with consistency across all environments. |
| 6 | Data classifications are defined and used | Classification must be automated for all data at the point of
creation or ingestion and must be always on. Classification is
automated for the following:
|
| 7 | Data entitlements are managed, enforced, and tracked | This control requires the following:
|
| 8 | Ethical access, use, and outcomes of data are managed | The data consumption purpose must be provided for all data sharing agreements that involve sensitive data. The purpose must specify the type of data required and, for global organizations, the country or legal entity scope. |
| 9 | Data is secured, and controls are evidenced | This control requires the following:
|
| 10 | A data privacy framework is defined and operational | Data protection impact assessments (DPIAs) must be automatically triggered for all personal data according to its jurisdiction. |
| 11 | The data lifecycle is planned and managed | Data retention, archiving, and purging must be managed according to a defined retention schedule. |
| 12 | Data quality is managed | Data quality measurement must be enabled for sensitive data with metrics distributed when available. |
| 13 | Cost management principles are established and applied | Technical design principles are established and applied. Cost metrics that are directly associated with data use, storage, and movement must be available in the catalog. |
| 14 | Data provenance and lineage are understood | Data lineage information must be available for all sensitive data. This information must at a minimum include the source from which the data was ingested or in which it was created in a cloud environment. |
1. Data control compliance
This control requires that you can verify that all sensitive data is monitored for compliance with this framework using metrics.
The architecture uses metrics that show the extent to which each of the key controls are operational. The architecture also includes dashboards that indicate when the metrics don't meet defined thresholds.
The architecture includes detectors that publish findings and remediation recommendations when data assets don't meet a key control. These findings and recommendations are in JSON format and published to a Pub/Sub topic for distribution to subscribers. You can integrate your internal service desk or service management tools with the Pub/Sub topic so that incidents are automatically created in your ticketing system.
The architecture uses Dataflow to create an example subscriber to the findings events, which are then stored in a BigQuery instance that runs in the Data Governance project. Using a number of supplied views, you can query the data using BigQuery Studio in the Google Cloud console. You can also create reports using Looker Studio or other BigQuery-compatible business intelligence tools. Reports that you can view include the following:
- Last run findings summary
- Last run findings detail
- Last run metadata
- Last run data assets in scope
- Last run dataset statistics
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Pub/Sub publishes findings.
- Dataflow loads findings into a BigQuery instance.
- BigQuery stores the findings data and provides summary views.
- Looker Studio provides dashboards and reports.
The following screenshot shows a sample Looker Studio summary dashboard.
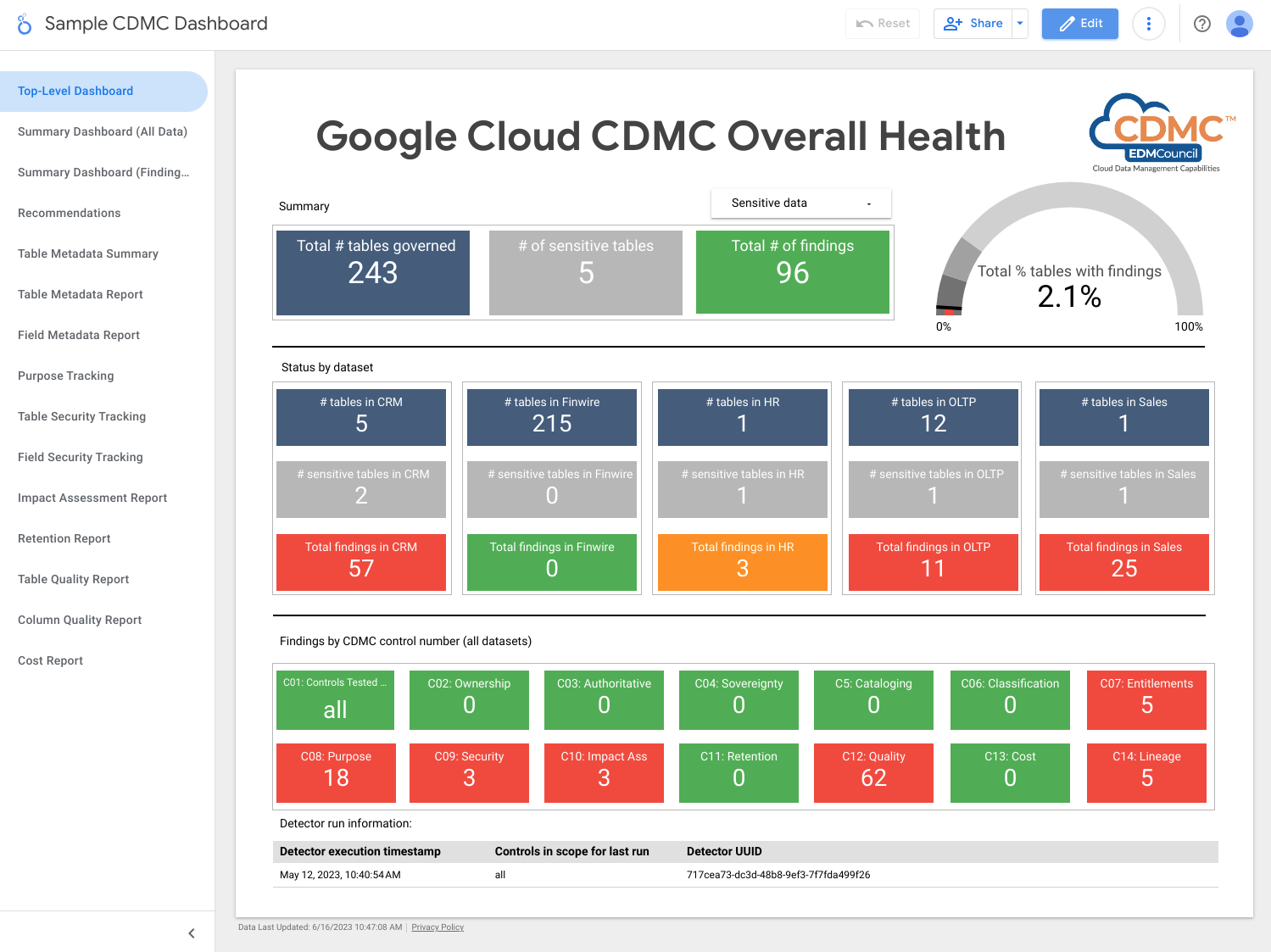
The following screenshot shows a sample view of findings by data asset.
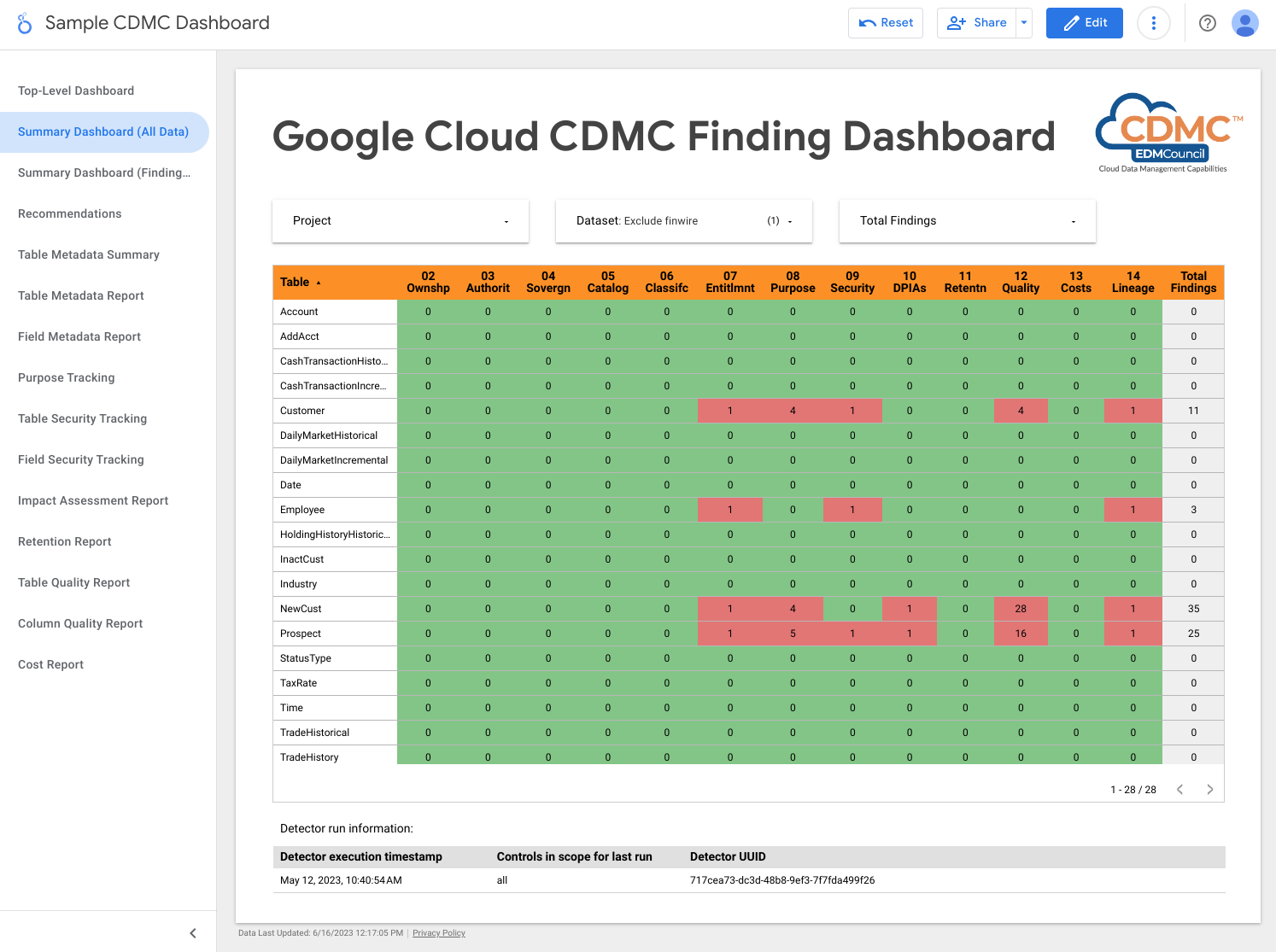
2. Data ownership is established for both migrated and cloud-generated data
To meet the requirements of this control, the architecture automatically reviews the data in the BigQuery data warehouse and adds data classification tags that indicate that owners are identified for all sensitive data.
Data Catalog, which is a feature of Dataplex, handles two types of metadata: technical metadata and business metadata. For a given project, Data Catalog automatically catalogs BigQuery datasets, tables, and views and populates the technical metadata. Synchronization between the catalog and data assets is maintained on a near real-time basis.
The architecture uses Tag Engine to add the following business metadata tags to
a CDMC controls tag template in Data Catalog:
is_sensitive: whether the data asset contains sensitive data (see Control 6 for data classification)owner_name: the owner of the dataowner_email: the email address of the owner
The tags are populated using defaults that are stored in a reference BigQuery table in the Data governance project.
By default, the architecture sets the ownership metadata at the table level, but you can change the architecture so that metadata is set at the column level. For more information, see Data Catalog tags and tag templates.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data and the other stores the defaults for data asset ownership.
- Data Catalog stores ownership metadata through tag templates and tags.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture checks whether sensitive data is assigned an owner name tag.
3. Data sourcing and consumption are governed and supported by automation
This control requires classification of data assets and a data register of
authoritative sources and authorized distributors. The architecture uses
Data Catalog to add the is_authoritative tag to the CDMC
controls tag template. This tag defines whether the data asset is
authoritative.
Data Catalog catalogs BigQuery datasets, tables,
and views with technical metadata and business metadata. Technical metadata is
automatically populated and includes the resource URL, which is the location of
the provisioning point. Business metadata is defined in the Tag Engine
configuration file and includes the is_authoritative tag.
During the next scheduled run, Tag Engine populates the is_authoritative tag
in the CDMC controls tag template from default values stored in a reference
table in BigQuery.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data and the other stores the defaults for the data asset authoritative source.
- Data Catalog stores authoritative source metadata through tags.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture checks whether sensitive data is assigned the authoritative source tag.
4. Data sovereignty and cross-border data movement are managed
This control requires the architecture to inspect the data registry for region-specific storage requirements and enforce usage rules. A report describes the geographical location of data assets.
The architecture uses Data Catalog to add the
approved_storage_location tag to the CDMC controls tag template. This tag
defines the geographic location that the data asset is permitted to be stored
in.
The actual location of the data is stored as technical metadata in BigQuery table details. BigQuery doesn't let administrators change the location of a dataset or table. Instead, if administrators want to change data location, they must copy the dataset.
The
resource locations Organization Policy Service constraint
defines the Google Cloud regions that you can store data in. By default,
the architecture sets the constraint on the Confidential data project, but you
can set the constraint at an organization or folder level if preferred. Tag
Engine replicates the permitted locations to the Data Catalog tag
template and stores the location in the approved_storage_location tag. If you
activate Security Command Center Premium tier, and someone updates the resource locations
Organization Policy Service constraint, Security Command Center generates
vulnerability findings
for resources stored outside of the updated policy.
Access Context Manager defines the geographic location that users must be in before they can access data assets. Using access levels, you can specify which regions that the requests can come from. You then add the access policy to the VPC Service Controls perimeter for the Confidential data project.
To track data movement, BigQuery maintains a full audit trail for every job and query against each dataset. The audit trail is stored in the BigQuery Information Schema Jobs view.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Organization Policy Service defines and enforces the resource locations constraint.
- Access Context Manager defines the locations that users can access data from.
- Two BigQuery data warehouses: one stores the confidential data and the other hosts a remote function which is used to inspect the location policy.
- Data Catalog stores approved storage locations as tags.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
- Cloud Logging writes the audit logs.
- Security Command Center reports on any findings related to resource location or data access.
To detect issues related to this control, the architecture includes a finding for whether the approved locations tag includes the location of the sensitive data.
5. Data catalogs are implemented, used, and interoperable
This control requires that a data catalog exists, and that the architecture can scan new and updated assets to add metadata as required.
To meet the requirements of this control, the architecture uses Data Catalog. Data Catalog automatically logs Google Cloud assets, including BigQuery datasets, tables, and views. When you create a new table in BigQuery, Data Catalog automatically registers the new table's technical metadata and schema. When you update a table in BigQuery, Data Catalog updates its entries almost instantaneously.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data and the other stores the non-confidential data.
- Data Catalog stores the technical metadata for tables and fields.
By default, in this architecture, Data Catalog stores technical metadata from BigQuery. If required, you can integrate Data Catalog with other data sources.
6. Data classifications are defined and used
This assessment requires that data can be classified based on its sensitivity, such as whether it's PII, identifies clients, or meets some other standard that your organization defines. To meet the requirements of this control, the architecture creates a report of data assets and their sensitivity. You can use this report to verify whether the sensitivity settings are correct. In addition, each new data asset or change to an existing data asset results in an update to the data catalog.
Classifications are stored in the sensitive_category tag in the
Data Catalog tag template at the table level and the column level. A
classification reference table lets you rank the available Sensitive Data Protection
information types
(infoTypes), with higher rankings for more sensitive content.
To meet the requirements of this control, the architecture uses Sensitive Data Protection, Data Catalog, and Tag Engine to add the following tags to sensitive columns in BigQuery tables:
is_sensitive: whether the data asset contains sensitive informationsensitive_category: the category of the data; one of the following:- Sensitive Personal Identifiable Information
- Personal Identifiable Information
- Sensitive Personal Information
- Personal Information
- Public Information
You can change the data categories to meet your requirements. For example, you can add the Material Non-Public Information (MNPI) classification.
After Sensitive Data Protection
inspects the data,
Tag Engine reads the per-asset DLP results tables to compile the findings. If
a table contains columns with one or more sensitive infoTypes, the most notable
infoType is determined and both the sensitive columns and the whole table are
tagged as the category that has the highest rank. Tag Engine also assigns a
corresponding
policy tag
to the column and assigns the is_sensitive boolean tag to the table.
You can use Cloud Scheduler to automate the Sensitive Data Protection inspection.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Four BigQuery data warehouses store the following
information:
- Confidential data
- Sensitive Data Protection results information
- Data classification reference data
- Tag export information
- Data Catalog stores the classification tags.
- Sensitive Data Protection inspects assets for sensitive infoTypes.
- Compute Engine runs the Inspect Datasets script, which triggers a Sensitive Data Protection job for each BigQuery dataset.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture includes the following findings:
- Whether sensitive data is assigned a sensitive category tag.
- Whether sensitive data is assigned a column-level sensitivity type tag.
7. Data entitlements are managed, enforced, and tracked
By default, only creators and owners are assigned entitlements and access to sensitive data. In addition, this control requires that the architecture tracks all access to sensitive data.
To meet the requirements of this control, the architecture uses the cdmc
sensitive data classification policy tag taxonomy in BigQuery to
control access to columns that contain confidential data in
BigQuery tables. The taxonomy includes the following policy
tags:
- Sensitive Personal Identifiable Information
- Personal Identifiable Information
- Sensitive Personal Information
- Personal Information
Policy tags let you control who can view sensitive columns in
BigQuery tables. The architecture maps these policy tags to
sensitivity classifications which were derived from Sensitive Data Protection
infoTypes. For example, the sensitive_personal_identifiable_information policy
tag and the sensitive category maps to infoTypes such as AGE, DATE_OF_BIRTH,
PHONE_NUMBER, and EMAIL_ADDRESS.
The architecture uses Identity and Access Management (IAM) to manage the groups, users, and service accounts that require access to the data. IAM permissions are granted to a given asset for table-level access. In addition, column-level access based on policy tags allows for fine-grained access to sensitive data assets. By default, users don't have access to columns that have defined policy tags.
To help ensure that only authenticated users can access data, Google Cloud uses Cloud Identity, which you can federate with your existing identity providers to authenticate users.
This control also requires that the architecture checks regularly for data assets that don't have entitlements defined. The detector, which is managed by Cloud Scheduler, checks for the following scenarios:
- A data asset includes a sensitive category, but there isn't a related policy tag.
- A category doesn't match the policy tag.
When these scenarios happen, the detector generates findings that are published
by Pub/Sub, and then are written to the events table in
BigQuery by Dataflow. You can then distribute the
findings to your remediation tool, as described in
1. Data control compliance.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- A BigQuery data warehouse stores the confidential data and the policy tag bindings for fine-grained access controls.
- IAM manages access.
- Data Catalog stores the table-level and column-level tags for the sensitive category.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
To detect issues related to this control, the architecture checks whether sensitive data has a corresponding policy tag.
8. Ethical access, use, and outcomes of data are managed
This control requires the architecture to store data sharing agreements from
both the data provider and data consumers, including a list of approved
consumption purposes. The consumption purpose for the sensitive data is then
mapped to entitlements stored in BigQuery using
query labels.
When a consumer queries sensitive data in BigQuery, they must
specify a valid purpose which matches their entitlement (for example, SET @@query_label = “use:3”;).
The architecture uses Data Catalog to add the following tags to
the CDMC controls tag template. These tags represent the data sharing
agreement with the data provider:
approved_use: the approved use or users of the data assetsharing_scope_geography: the list of geographic locations that the data asset can be shared insharing_scope_legal_entity: the list of agreed entities that can share the data asset
A separate BigQuery data warehouse includes the
entitlement_management dataset with the following tables:
provider_agreement: the data sharing agreement with the data provider, including the agreed legal entity and geographic scope. This data is the defaults for theshared_scope_geographyandsharing_scope_legal_entitytags.consumer_agreement: the data sharing agreement with the data consumer, including the agreed legal entity and geographic scope. Each agreement is associated with an IAM binding for the data asset.use_purpose: the consumption purpose such as the usage description and permitted operations for the data assetdata_asset: information about the data asset, such as the asset name and details about the data owner.
To audit data sharing agreements, BigQuery maintains a full audit trail for every job and query against each dataset. The audit trail is stored in the BigQuery Information Schema Jobs view. After you associate a query label with a session and run queries inside the session, you can collect audit logs for queries with that query label. For more information, see the Audit log reference for BigQuery.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data and the other stores the entitlement data, which includes the provider and consumer data sharing agreements and the approved usage purpose.
- Data Catalog stores the provider data sharing agreement information as tags.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture includes the following findings:
- Whether there is an entry for a data asset in the
entitlement_managementdataset. - Whether an operation is performed on a sensitive table with an expired
use case (for example, the
valid_until_datein theconsumer_agreement tablehas passed). - Whether an operation is performed on a sensitive table with an incorrect label key.
- Whether an operation is performed on a sensitive table with either a blank or an unapproved use-case label value.
- Whether a sensitive table is queried with an unapproved operation method
(for example,
SELECTorINSERT). - Whether the recorded purpose that the consumer specified when querying the sensitive data matches the data sharing agreement.
9. Data is secured and controls are evidenced
This control requires the implementation of data encryption and de-identification to help protect sensitive data and provide a record of these controls.
This architecture builds on Google default security, which includes encryption at rest. In addition, the architecture lets you manage your own keys using customer-managed encryption keys (CMEK). Cloud KMS lets you encrypt your data with software-backed encryption keys or FIPS 140-2 Level 3 validated hardware security modules (HSMs).
The architecture uses column-level dynamic data masking configured through policy tags, and stores confidential data within a separate VPC Service Controls perimeter. You can also add application-level de-identification, which you can implement either on-premise or as part of the data ingestion pipeline.
By default, the architecture implements CMEK encryption with HSMs, but also supports Cloud External Key Manager (Cloud EKM).
The following table describes the example security policy that the architecture implements for the us-central1 region. You can adapt the policy to meet your requirements, including by adding different policies for different regions.
| Data sensitivity | Default encryption method | Other permitted encryption methods | Default de-identification method | Other permitted de-identification methods |
|---|---|---|---|---|
| Public Information | Default Encryption | Any | None | Any |
| Sensitive Personal Identifiable Information | CMEK with HSM | EKM | Nullify | SHA-256 Hash or Default Masking Value |
| Personal Identifiable Information | CMEK with HSM | EKM | SHA-256 Hash | Nullify or Default Masking Value |
| Sensitive Personal Information | CMEK with HSM | EKM | Default Masking Value | SHA-256 Hash or Nullify |
| Personal Information | CMEK with HSM | EKM | Default Masking Value | SHA-256 Hash or Nullify |
The architecture uses Data Catalog to add the encryption_method
tag to the table-level CDMC controls tag template. The encryption_method
defines the encryption method that is used by the data asset.
In addition, the architecture creates a security policy template tag to
identify which de-identification method is applied to a particular field. The
architecture uses the platform_deid_method which is applied using dynamic
data masking. You can add the app_deid_method, and can populate it using the
Dataflow and Sensitive Data Protection data ingestion pipelines that are included in
the secured data warehouse blueprint.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two optional instances of Dataflow, one performs application-level de-identification and the other performs re-identification.
- Three BigQuery data warehouses: one stores the confidential data, one stores the non-confidential data, and the third stores the security policy.
- Data Catalog stores the encryption and de-identification tag templates.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub published findings.
To detect issues related to this control, the architecture includes the following findings:
- The value for the encryption method tag doesn't match the permitted encryption methods for specified sensitivity and location.
- A table contains sensitive columns but the Security Policy Template tag contains an invalid platform-level de-identification method.
- A table contains sensitive columns but the Security Policy Template tag is missing.
10. A data privacy framework is defined and operational
This control requires that the architecture inspects the data catalog and classifications to determine whether you must create a data protection impact assessment (DPIA) report or a privacy impact assessment (PIA) report. Privacy assessments vary significantly between geographies and regulators. To determine whether an impact assessment is required, the architecture must consider the residency of the data, and the residency of the data subject.
The architecture uses Data Catalog to add the following tags to
the Impact assessment tag template:
subject_locations: the location of the subjects referred to by the data in this asset.is_dpia: whether a data privacy impact assessment (DPIA) was completed for this asset.is_pia: whether a privacy impact assessment (PIA) was completed for this asset.impact_assessment_reports: external link to where the impact assessment report is stored.most_recent_assessment: the date of the most recent impact assessment.oldest_assessment: the date of the first impact assessment.
Tag Engine adds these tags to each sensitive data asset, as defined by control 6. The detector validates these tags against a policy table in BigQuery, which includes valid combinations of data residency, subject location, data sensitivity (for example, whether it's PII), and what impact assessment type (either PIA or DPIA) is required.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Four BigQuery data warehouses store the following
information:
- Confidential data
- Non-confidential data
- Impact assessment policy and entitlements timestamps
- Tag exports that are used for the dashboard
- Data Catalog stores the impact assessment details in tags within tag templates.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture includes the following findings:
- Sensitive data exists without an impact assessment template.
- Sensitive data exists without a link to a DPIA or PIA report.
- Tags don't meet the requirements in the policy table.
- The impact assessment is older than the most recently approved entitlement for the data asset in the consumer agreement table.
11. The data lifecycle is planned and managed
This control requires the ability to inspect all data assets to determine that a data lifecycle policy exists and is adhered to.
The architecture uses Data Catalog to add the following tags to
the CDMC controls tag template:
retention_period: the time, in days, to retain the tableexpiration_action: whether to archive or purge the table when the retention period ends
By default, the architecture uses the following retention period and expiration action:
| Data category | Retention period, in days | Expiration action |
|---|---|---|
| Sensitive Personal Identifiable Information | 60 | Purge |
| Personal Identifiable Information | 90 | Archive |
| Sensitive Personal Information | 180 | Archive |
| Personal information | 180 | Archive |
Record Manager, an open source asset for BigQuery, automates the purging and archiving of BigQuery tables based on the above tag values and a configuration file. The purging procedure sets an expiration date on a table and creates a snapshot table with an expiration time that is defined in the Record Manager configuration. By default, the expiration time is 30 days. During the soft-deletion period, you can retrieve the table. The archival procedure creates an external table for each BigQuery table that passes its retention period. The table is stored in Cloud Storage in parquet format and upgraded to a BigLake table which allows the external file to be tagged with metadata in Data Catalog.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data, and the other stores the data retention policy.
- Two Cloud Storage instances, one provides archive storage and the other stores records.
- Data Catalog stores the retention period and action in tag templates and the tags.
- Two Cloud Run instances, one runs the Record Manager and the other deploys the detectors.
- Three Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Another instance runs Record Manager, which automates the purging and archiving of BigQuery tables.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture includes the following findings:
- For sensitive assets, ensure that the retention method is aligned with the policy for the asset's location.
- For sensitive assets, ensure that the retention period is aligned with the policy for the asset's location.
12. Data quality is managed
This control requires the ability to measure the quality of the data based on data profiling or user-defined metrics.
The architecture includes the ability to define data quality rules for either an individual or aggregate value and assign thresholds to a specific table column. It includes tag templates for correctness and completeness. Data Catalog adds the following tags to each tag template:
column_name: the name of the column that the metric applies tometric: the name of the metric or quality rulerows_validated: the number of validated rowssuccess_percentage: the percentage of values which satisfy this metricacceptable_threshold: the acceptable threshold for this metricmeets_threshold: whether the quality score (thesuccess_percentagevalue) meets the acceptable thresholdmost_recent_run: the most recent time that the metric or quality rule was run
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Three BigQuery data warehouses: one stores the sensitive data, one stores the non-sensitive data, and the third stores the quality rule metrics.
- Data Catalog stores the data quality results in tag templates and tags.
- Cloud Scheduler defines when Cloud Data Quality Engine runs.
- Three Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- The third instance runs the Cloud Data Quality Engine.
- Cloud Data Quality Engine defines data quality rules and schedules data quality checks for tables and columns.
- Pub/Sub publishes findings.
A Looker Studio dashboard displays the data quality reports for both the table levels and column levels.
To detect issues related to this control, the architecture includes the following findings:
- Data is sensitive, but no data quality tag templates are applied (correctness and completeness).
- Data is sensitive but the data quality tag isn't applied to the sensitive column.
- Data is sensitive, but data quality results aren't within the threshold set in the rule.
- Data isn't sensitive and data quality results aren't within the threshold that was set by the rule.
As an alternative to the Cloud Data Quality Engine, you can configure Dataplex data quality tasks.
13. Cost management principles are established and applied
This control requires the ability to inspect data assets to confirm cost usage, based on policy requirements and the data architecture. Cost metrics should be comprehensive and not just limited to storage use and movement.
The architecture uses Data Catalog to add the following tags the
cost_metrics tag template:
total_query_bytes_billed: total number of query bytes that were billed for this data asset since the start of the current month.total_storage_bytes_billed: total number of storage bytes that were billed for this data asset since the start of the current month.total_bytes_transferred: sum of bytes transferred cross-region into this data asset.estimated_query_cost: estimated query cost, in US dollars, for the data asset for the current month.estimated_storage_cost: estimated storage cost, in US dollars, for the data asset for the current month.estimated_egress_cost: estimated egress in US dollars for the current month in which data asset was used as a destination table.
The architecture exports pricing information from Cloud Billing to a
BigQuery table named cloud_pricing_export.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Cloud Billing provides billing information.
- Data Catalog stores the cost information in tag templates and tags.
- BigQuery stores the exported pricing information and the query historical job information through its built-in INFORMATION_SCHEMA view.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture checks whether sensitive data assets exist without having cost metrics associated with them.
14. Data provenance and lineage are understood
This control requires the ability to inspect the traceability of the data asset from its source and any changes to the data asset lineage.
To maintain information about data provenance and lineage, the architecture uses the built-in Data Lineage features in Data Catalog. Additionally, the data ingestion scripts define the ultimate source and add the source as an additional node to the data lineage graph.
To meet the requirements of this control, the architecture uses
Data Catalog to add the ultimate_source tag to the CDMC
controls tag template. The ultimate_source tag defines the source for this
data asset.
The following diagram shows the services that apply to this control.

To meet the requirements of this control, the architecture uses the following services:
- Two BigQuery data warehouses: one stores the confidential data, and the other stores the ultimate source data.
- Data Catalog stores the ultimate source in tag templates and tags.
- Data ingestion scripts load the data from Cloud Storage, define the ultimate source and add the source to the data lineage graph.
- Two Cloud Run instances, as follows:
- One instance runs Report Engine, which checks whether tags are applied and publishes results.
- Another instance runs Tag Engine, which tags the data in the secured data warehouse.
- Pub/Sub publishes findings.
To detect issues related to this control, the architecture includes the following checks:
- Sensitive data is identified with no ultimate source tag.
- Lineage graph is not populated for sensitive data assets.
Tag reference
This section describes the tag templates and tags that this architecture uses to meet the requirements of the CDMC key controls.
Table-level CDMC control tag templates
The following table lists the tags that are part of the CDMC control tag template and that are applied to tables.
| Tag | Tag ID | Applicable key control |
|---|---|---|
| Approved Storage Location | approved_storage_location |
4 |
| Approved Use | approved_use |
8 |
| Data Owner Email | data_owner_email |
2 |
| Data Owner Name | data_owner_name |
2 |
| Encryption Method | encryption_method |
9 |
| Expiration Action | expiration_action |
11 |
| Is Authoritative | is_authoritative |
3 |
| Is Sensitive | is_sensitive |
6 |
| Sensitive Category | sensitive_category |
6 |
| Sharing Scope Geography | sharing_scope_geography |
8 |
| Sharing Scope Legal Entity | sharing_scope_legal_entity |
8 |
| Retention Period | retention_period |
11 |
| Ultimate Source | ultimate_source |
14 |
Impact Assessment tag template
The following table lists the tags that are part of the Impact Assessment tag template and that are applied to tables.
| Tag | Tag ID | Applicable key control |
|---|---|---|
| Subject Locations | subject_locations |
10 |
| Is DPIA impact assessment | is_dpia |
10 |
| Is PIA impact assessment | is_pia |
10 |
| Impact assessment reports | impact_assessment_reports |
10 |
| Most recent impact assessment | most_recent_assessment |
10 |
| Oldest impact assessment | oldest_assessment |
10 |
Cost Metrics tag template
The following table lists the tags that are part of the Cost Metrics tag template and that are applied to tables.
| Tag | Tab ID | Applicable key control |
|---|---|---|
| Estimated Query Cost | estimated_query_cost |
13 |
| Estimated Storage Cost | estimated_storage_cost |
13 |
| Estimated Egress Cost | estimated_egress_cost |
13 |
| Total Query Bytes Billed | total_query_bytes_billed |
13 |
| Total Storage Bytes Billed | total_storage_bytes_billed |
13 |
| Total Bytes Transferred | total_bytes_transferred |
13 |
Data Sensitivity tag template
The following table lists the tags that are part of the Data Sensitivity tag template and that are applied to fields.
| Tag | Tag ID | Applicable key control |
|---|---|---|
| Sensitive Field | sensitive_field |
6 |
| Sensitive Type | sensitive_category |
6 |
Security Policy tag template
The following table lists the tags that are part of the Security Policy tag template and that are applied to fields.
| Tag | Tag ID | Applicable key control |
|---|---|---|
| Application De-Identification Method | app_deid_method |
9 |
| Platform De-Identification Method | platform_deid_method |
9 |
Data Quality tag templates
The following table lists the tags that are part of the Completeness and Correctness Data Quality tag templates and that are applied to fields.
| Tag | Tag ID | Applicable key control |
|---|---|---|
| Acceptable Threshold | acceptable_threshold |
12 |
| Column Name | column_name |
12 |
| Meets Threshold | meets_threshold |
12 |
| Metric | metric |
12 |
| Most Recent Run | most_recent_run |
12 |
| Rows Validated | rows_validated |
12 |
| Success Percentage | success_percentage |
12 |
Field-level CDMC policy tags
The following table lists the policy tags that are part of the CDMC Sensitive Data Classification policy tag taxonomy and that are applied to fields. These policy tags restrict field-level access and enable platform level data de-identification.
| Data Classification | Tag Name | Applicable key control |
|---|---|---|
| Personal Identifiable Information | personal_identifiable_information |
7 |
| Personal Information | personal_information |
7 |
| Sensitive Personal Identifiable Information | sensitive_personal_identifiable_information |
7 |
| Sensitive Personal Information | sensitive_personal_data |
7 |
Prepopulated technical metadata
The following table lists the technical metadata that is synchronized by default in Data Catalog for all BigQuery data assets.
| Metadata | Applicable key control |
|---|---|
| Asset Type | — |
| Creation Time | — |
| Expiration Time | 11 |
| Location | 4 |
| Resource URL | 3 |
What's next
- Learn more about CDMC.
- Read about the security controls used by the secured data warehouse blueprint.
- Discover Data Catalog.
- Learn more about Dataplex.
- Learn more about Tag Engine.
- Implement this solution using the Google Cloud CDMC Reference Architecture in GitHub.