After developing an agent, you can use Gen AI evaluation service to evaluate the agent's ability to complete tasks and goals for a given use case.
Define evaluation metrics
Begin with an empty list of metrics (i.e. metrics = []) and add the relevant
metrics to it. To include additional metrics:
Final response
Final response evaluation follows the same process as model-based evaluation. For details, see Define your evaluation metrics.
Exact match
metrics.append("trajectory_exact_match")
If the predicted trajectory is identical to the reference trajectory, with the
exact same tool calls in the exact same order, the trajectory_exact_match
metric returns a score of 1, otherwise 0.
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
In-order match
metrics.append("trajectory_in_order_match")
If the predicted trajectory contains all the tool calls from the reference
trajectory in the same order, and may also have extra tool calls, the
trajectory_in_order_match metric returns a score of 1, otherwise 0.
Input parameters:
predicted_trajectory: The predicted trajectory used by the agent to reach the final response.reference_trajectory: The expected predicted trajectory for the agent to satisfy the query.
Any-order match
metrics.append("trajectory_any_order_match")
If the predicted trajectory contains all the tool calls from the reference
trajectory, but the order doesn't matter and may contain extra tool calls,
then the trajectory_any_order_match metric returns a score of 1, otherwise 0.
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Precision
metrics.append("trajectory_precision")
The trajectory_precision metric measures how many of the tool calls in the
predicted trajectory are actually relevant or correct according to the
reference trajectory. It is a float value in the range of [0, 1]: the
higher the score, more precise the predicted trajectory.
Precision is calculated as follows: Count how many actions in the predicted trajectory also appear in the reference trajectory. Divide that count by the total number of actions in the predicted trajectory.
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Recall
metrics.append("trajectory_recall")
The trajectory_recall metric measures how many of the essential tool calls
from the reference trajectory are actually captured in the predicted
trajectory. It is a float value in the range of [0, 1]: the higher the
score, the better the recall of the predicted trajectory.
Recall is calculated as follows: Count how many actions in the reference trajectory also appear in the predicted trajectory. Divide that count by the total number of actions in the reference trajectory.
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Single tool use
from vertexai.preview.evaluation import metrics
metrics.append(metrics.TrajectorySingleToolUse(tool_name='tool_name'))
The trajectory_single_tool_use metric checks if a specific tool that is
specified in the metric spec is used in the predicted trajectory. It doesn't
check the order of tool calls or how many times the tool is used, just whether
it's present or not. It is a value of 0 if the tool is absent, 1 otherwise.
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.
Custom
You can define a custom metric as follows:
from vertexai.preview.evaluation import metrics
def word_count(instance):
response = instance["response"]
score = len(response.split(" "))
return {"word_count": score}
metrics.append(
metrics.CustomMetric(name="word_count", metric_function=word_count)
)
The following two performance metrics are always included in the results. You
don't need to specify them in EvalTask:
latency(float): Time taken (in seconds) by the agent to respond.failure(bool):0if the agent invocation succeeded,1otherwise.
Prepare evaluation dataset
To prepare your dataset for final response or trajectory evaluation:
Final response
The data schema for final response evaluation is similar to that of model response evaluation.
Exact match
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
In-order match
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The predicted trajectory used by the agent to reach the final response.reference_trajectory: The expected predicted trajectory for the agent to satisfy the query.
Any-order match
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Precision
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Recall
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.reference_trajectory: The expected tool use for the agent to satisfy the query.
Single tool use
The evaluation dataset needs to provide the following inputs:
Input parameters:
predicted_trajectory: The list of tool calls used by the agent to reach the final response.
For illustration purposes, the following is an example of an evaluation dataset.
import pandas as pd
eval_dataset = pd.DataFrame({
"predicted_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_3", "updates": {"status": "OFF"}}
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_z"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
]
],
"reference_trajectory": [
[ # example 1
{
"tool_name": "set_device_info",
"tool_input": {"device_id": "device_2", "updates": {"status": "OFF"}},
},
],
[ # example 2
{
"tool_name": "get_user_preferences",
"tool_input": {"user_id": "user_y"},
}, {
"tool_name": "set_temperature",
"tool_input": {"location": "Living Room", "temperature": 23},
},
],
],
})
Example datasets
We have provided the following example datasets to demonstrate how you can evaluate agents:
"on-device": Evaluation dataset for an On-Device Home Assistant. The agent helps with queries such as "Schedule the air conditioning in the bedroom so that it is on between 11pm and 8am, and off the rest of the time.""customer-support": Evaluation dataset for a Customer Support Agent. The agent helps with queries such as "Can you cancel any pending orders and escalate any open support tickets?""content-creation": Evaluation dataset for a Marketing Content Creation Agent. The agent helps with queries such as "Reschedule campaign X to be a one-time campaign on social media site Y with a 50% reduced budget, only on December 25, 2024."
To import the example datasets:
Install and initialize the
gcloudCLI.Download the evaluation dataset.
On Device
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/on-device/eval_dataset.json .Customer Support
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/customer-support/eval_dataset.json .Content Creation
gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/content-creation/eval_dataset.json .Load the dataset examples
import json eval_dataset = json.loads(open('eval_dataset.json').read())
Generate evaluation results
To generate evaluation results, run the following code:
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(dataset=eval_dataset, metrics=metrics)
eval_result = eval_task.evaluate(runnable=agent)
View and interpret results
The evaluation results are displayed as follows:
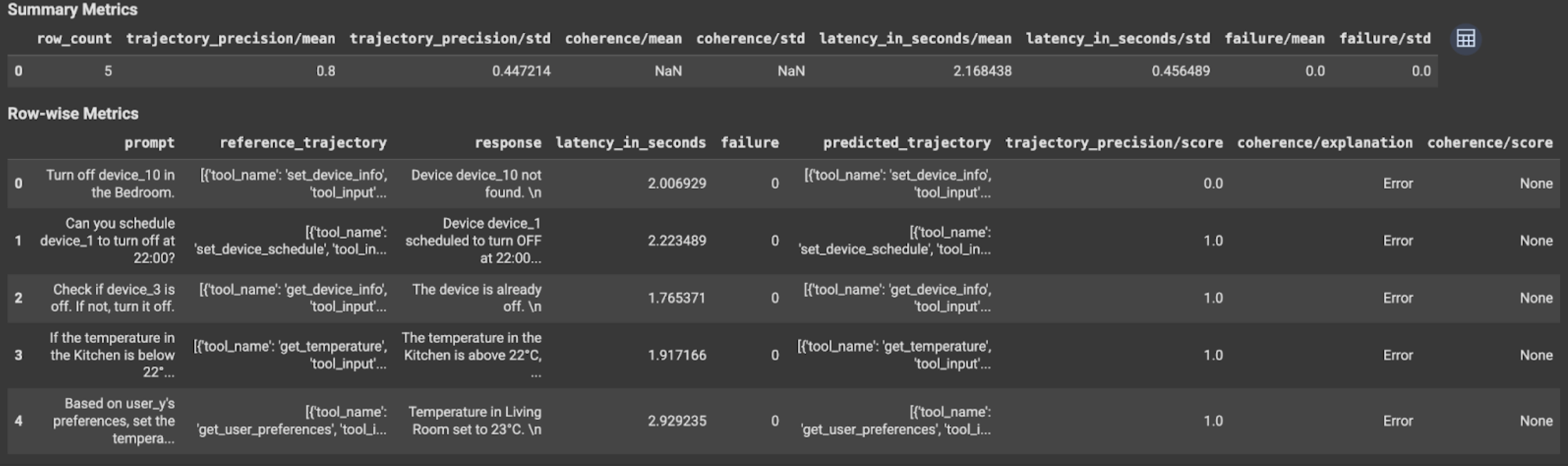
The evaluation results contain the following information:
Final response metrics
Row-wise metrics:
response: Final response generated by the agent.latency_in_seconds: Time taken (in seconds) to generate the response.failure: Indicates whether a valid response was generated or not.score: A score calculated for the response specified in the metric spec.explanation: The explanation for the score specified in the metric spec.
Summary metrics:
mean: Average score for all instances.standard deviation: Standard deviation for all the scores.
Trajectory metrics
Row-wise metrics:
predicted_trajectory: Sequence of tool calls followed by agent to reach the final response.reference_trajectory: Sequence of expected tool calls.score: A score calculated for the predicted trajectory and reference trajectory specified in the metric spec.latency_in_seconds: Time taken (in seconds) to generate the response.failure: Indicates whether a valid response was generated or not.
Summary metrics:
mean: Average score for all instances.standard deviation: Standard deviation for all the scores.
What's next
Try the following notebooks: