For improved performance in your data pipelines, you can push some transformation operations to BigQuery instead of Apache Spark. Transformation Pushdown refers to a setting that lets an operation in a Cloud Data Fusion data pipeline to be pushed to BigQuery as an execution engine. As a result, the operation and its data are transferred to BigQuery and the operation is performed there.
Transformation Pushdown improves the performance of pipelines that have
multiple complex
JOIN operations
or other supported transformations. Executing some transformations in
BigQuery may be faster than executing them in Spark.
Unsupported transformations and all preview transformations are executed in Spark.
Supported transformations
Transformation Pushdown is available in Cloud Data Fusion version 6.5.0 and later, but some of the following transformations are only supported in later versions.
JOIN operations
Transformation Pushdown is available for
JOINoperations in Cloud Data Fusion version 6.5.0 and later.Basic (on-keys) and advanced
JOINoperations are supported.Joins must have exactly two input stages for the execution to take place in BigQuery.
Joins that are configured to load one or more inputs into memory are executed in Spark instead of BigQuery, except in the following cases:
- If any of the inputs to the join is already pushed down.
- If you configured the join to be executed in SQL Engine (see the Stages to force execution option).
BigQuery Sink
Transformation Pushdown is available for the BigQuery Sink in Cloud Data Fusion version 6.7.0 and later.
When the BigQuery Sink follows a stage that has been executed in BigQuery, the operation that writes records into BigQuery is performed directly in BigQuery.
To improve performance with this sink, you need the following:
- The service account must have permission to create and update tables in the dataset used by the BigQuery Sink.
- The datasets used for Transformation Pushdown and the BigQuery Sink must be stored in the same location.
- The operation must be one of the following:
Insert(theTruncate Tableoption is not supported)UpdateUpsert
GROUP BY aggregations
Transformation Pushdown is available for GROUP BY aggregations in
Cloud Data Fusion version 6.7.0 and later.
GROUP BY aggregations in BigQuery are available for the
following operations:
AvgCollect List(null values are removed from the output array)Collect Set(null values are removed from the output array)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
GROUP BY aggregations are executed in BigQuery in the following
cases:
- It follows a stage that has already been pushed down.
- You configured it to be executed in SQL Engine (see the Stages to force execution option).
Deduplicate aggregations
Transformation Pushdown is available for deduplicate aggregations in Cloud Data Fusion version 6.7.0 and later for the following operations:
- No filter operation is specified
ANY(a non-null value for the desired field)MIN(the minimum value for the specified field)MAX(the maximum value for the specified field)
The following operations are not supported:
FIRSTLAST
Deduplicate aggregations are executed in the SQL engine in the following cases:
- It follows a stage that has already been pushed down.
- You configured it to be executed in SQL Engine (see the Stages to force execution option).
BigQuery Source Pushdown
BigQuery Source Pushdown is available in Cloud Data Fusion versions 6.8.0 and later.
When a BigQuery Source follows a stage that's compatible for BigQuery pushdown, the pipeline can execute all compatible stages within BigQuery.
Cloud Data Fusion copies the records necessary to execute the pipeline within BigQuery.
When you use BigQuery Source Pushdown, the table partitioning and clustering properties are preserved, which lets you use these properties to optimize further operations, such as joins.
Additional requirements
To use BigQuery Source Pushdown, the following requirements must be in place:
The service account configured for BigQuery Transformation Pushdown must have permissions to read tables in the BigQuery Source's dataset.
The Datasets used in the BigQuery Source and the dataset configured for Transformation Pushdown must be stored in the same location.
Window aggregations
Transformation Pushdown is available for Window aggregations in Cloud Data Fusion versions 6.9 and later. Window aggregations in BigQuery are supported for the following operations:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
Window aggregations are executed in BigQuery in the following cases:
- It follows a stage that has already been pushed down.
- You configured it to be executed in SQL Engine (see the Stages to force pushdown option).
Wrangler Filter Pushdown
Wrangler Filter Pushdown is available in Cloud Data Fusion versions 6.9 and later.
When using the Wrangler plugin, you can push filters, known as Precondition
operations, to be executed in BigQuery instead of Spark.
Filter pushdown is only supported with the SQL mode for Preconditions, which was also released in version 6.9. In this mode, the plugin accepts a precondition expression in ANSI-standard SQL.
If the SQL mode is used for preconditions, Directives and User Defined Directives are disabled for the Wrangler plugin, as they're not supported with preconditions in SQL mode.
SQL mode for preconditions is unsupported for Wrangler plugins with multiple inputs when Transformation Pushdown is enabled. If used with multiple inputs, this Wrangler stage with SQL filter conditions is executed in Spark.
Filters are executed in BigQuery in the following cases:
- It follows a stage that has already been pushed down.
- You configured it to be executed in SQL Engine (see the Stages to force pushdown option).
Metrics
For more information about the metrics that Cloud Data Fusion provides for the part of the pipeline that's executed in BigQuery, see BigQuery pushdown pipeline metrics.
When to use Transformation Pushdown
Executing transformations in BigQuery involves the following:
- Writing records into BigQuery for supported stages in your pipeline.
- Executing supported stages in BigQuery.
- Reading records from BigQuery after the supported transformations are executed, unless they are followed by a BigQuery Sink.
Depending on the size of your datasets, there might be considerable network overhead, which can have a negative impact on overall pipeline execution time when Transformation Pushdown is enabled.
Due to the network overhead, we recommend Transformation Pushdown in the following cases:
- Multiple supported operations are executed in sequence (with no steps between the stages).
- Performance gains from BigQuery executing the transformations, relative to Spark, outweighs the latency of data movement into and possibly out of BigQuery.
How it works
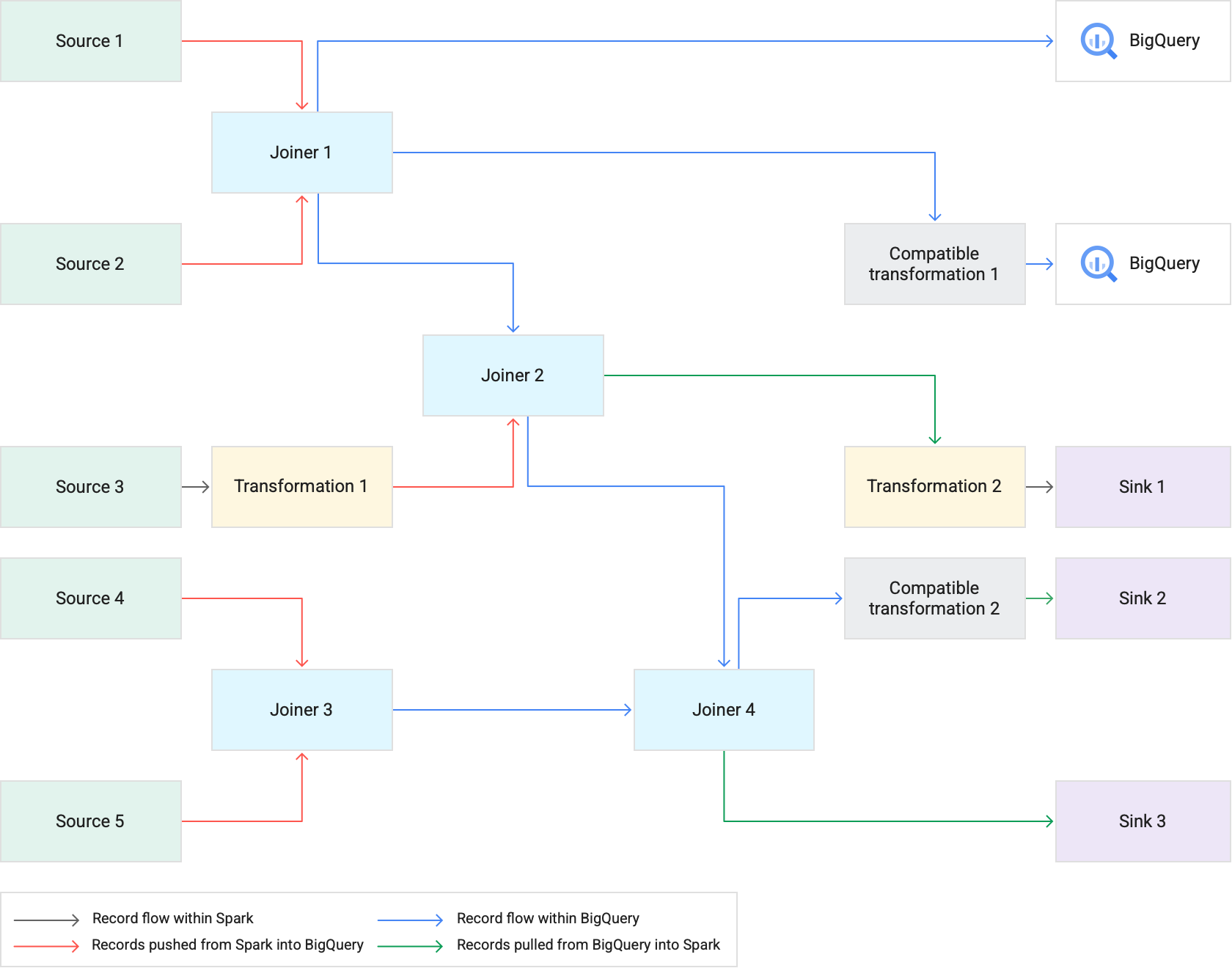
When you run a pipeline that uses Transformation Pushdown, Cloud Data Fusion executes supported transformation stages in BigQuery. All other stages in the pipeline are executed in Spark.
When executing transformations:
Cloud Data Fusion loads the input datasets into BigQuery by writing records into Cloud Storage, and then executing a BigQuery load job.
JOINoperations and supported transformations are then executed as BigQuery jobs using SQL statements.If further processing is needed after the jobs are executed, records can be exported from BigQuery to Spark. However, if the Attempt direct copy to BigQuery sinks option is enabled and the BigQuery Sink follows a stage that was executed in BigQuery, records are written directly to the destination BigQuery Sink table.
The following diagram shows how Transformation Pushdown executes supported transformations in BigQuery instead of Spark.
Best practices
Adjust cluster and executor sizes
To optimize the resource management in your pipeline, do the following:
Use the right number of cluster workers (nodes) for a workload. In other words, get the most out of the provisioned Dataproc cluster by fully using the available CPU and memory for your instance, while also benefiting from the execution speed of BigQuery for large jobs.
Improve the parallelism in your pipelines by using autoscaling clusters.
Adjust your resource configurations in the stages of your pipeline where records are pushed or pulled from BigQuery during your pipeline execution.
Recommended: Experiment with increasing the number of CPU cores for your executor resources (up to the number of CPU cores that your worker node uses). The executors optimize CPU use during the serialization and deserialization steps as data goes in and out of BigQuery. For more information, see Cluster sizing.
A benefit of executing transformations in BigQuery is that your
pipelines can run on smaller Dataproc clusters. If joins are the
most resource-intensive operations in your pipeline, you can experiment with
smaller cluster sizes, as the heavy JOIN operations are now performed in
BigQuery), allowing you to potentially reduce your overall
compute costs.
Retrieve data faster with the BigQuery Storage Read API
After BigQuery executes the transformations, your pipeline might have additional stages to execute in Spark. In Cloud Data Fusion version 6.7.0 and later, Transformation Pushdown supports the BigQuery Storage Read API, which improves latency and results in faster read operations into Spark. It can reduce the overall pipeline execution time.
The API reads records in parallel, so we recommend adjusting executor sizes accordingly. If resource-intensive operations are executed in BigQuery, reduce the memory allocation for the executors to improve parallelism when the pipeline runs (see Adjust cluster and executor sizes).
The BigQuery Storage Read API is disabled by default. You can enable it in execution environments where Scala 2.12 is installed (including Dataproc 2.0 and Dataproc 1.5).
Consider the dataset size
Consider the sizes of the datasets in the JOIN operations. For JOIN
operations that generate a substantial number of output records, such as
something that resembles a cross JOIN operation, the resulting dataset size
might be orders of magnitude larger than the input dataset. Also, consider the
overhead of pulling these records back into Spark when additional Spark
processing for these records occurs, such as a transformation or a sink, in the
context of the overall pipeline performance.
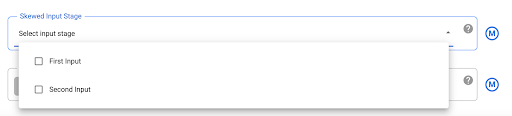
Mitigate skewed data
JOIN operations for heavily skewed data might cause the
BigQuery job to exceed the
resource utilization limits,
which causes the JOIN operation to fail. To prevent this, go to the Joiner
plugin settings and identify the skewed input in the Skewed Input Stage
field. This lets Cloud Data Fusion arrange the inputs in a way that reduces
the risk of the BigQuery statement from exceeding the limits.
What's next
- Learn how to enable Transformation Pushdown in Cloud Data Fusion.