This page describes the use case where you control access to Google Cloud resources at the namespace level when you migrate data from Cloud Storage to BigQuery.
To control access to Google Cloud resources, namespaces in Cloud Data Fusion use the Cloud Data Fusion API Service Agent by default.
For better data isolation, you can associate a customized IAM service account (known as a Per Namespace Service Account) with each namespace. The customized IAM service account, which can be different for different namespaces, lets you control access to Google Cloud resources between namespaces for pipeline design-time operations in Cloud Data Fusion, such as pipeline preview, Wrangler, and pipeline validation.
For more information, see Access control with namespace service accounts.
Scenario
In this use case, your marketing department migrates data from Cloud Storage to BigQuery using Cloud Data Fusion.
The marketing department has three teams: A, B, and C. Your objective is to establish a structured approach to control data access in Cloud Storage through Cloud Data Fusion namespaces corresponding to each team—A, B, and C, respectively.
Solution
The following steps show how you control access to Google Cloud resources with namespace service accounts, preventing unauthorized access between the datastores of different teams.
Associate an Identity and Access Management service account to each namespace
Configure an IAM service account in the namespace for each team (see Configure a namespace service account):
Set up the access control by adding a customized service account for Team A—for example,
team-a@pipeline-design-time-project.iam.gserviceaccount.com.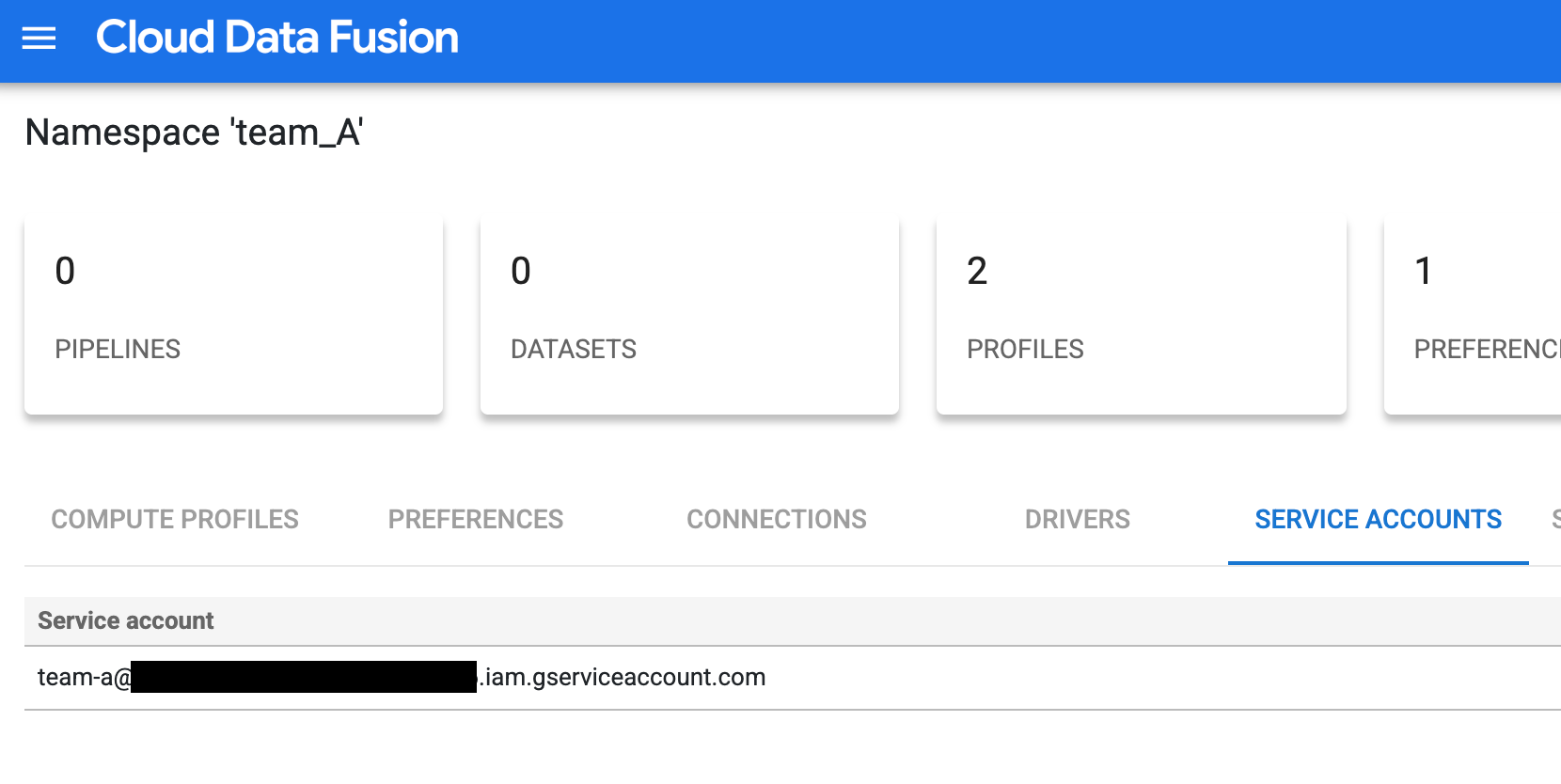
Figure 1: Add a customized service account for Team A. Repeat the configuration steps for Teams B and C to set up access control with similar customized service accounts.
Limit access to the Cloud Storage buckets
Limit the access to Cloud Storage buckets by giving appropriate permissions:
- Give the IAM service account the
storage.buckets.listpermission, required to list Cloud Storage buckets in the project. For more information, see Listing buckets. Give the IAM service account permission to access the objects in particular buckets.
For example, grant the Storage Object Viewer role to the IAM service account associated with the namespace
team_Aon the bucketteam_a1. This permission lets Team A view and list objects and managed folders, along with their metadata, in that bucket in an isolated design time environment.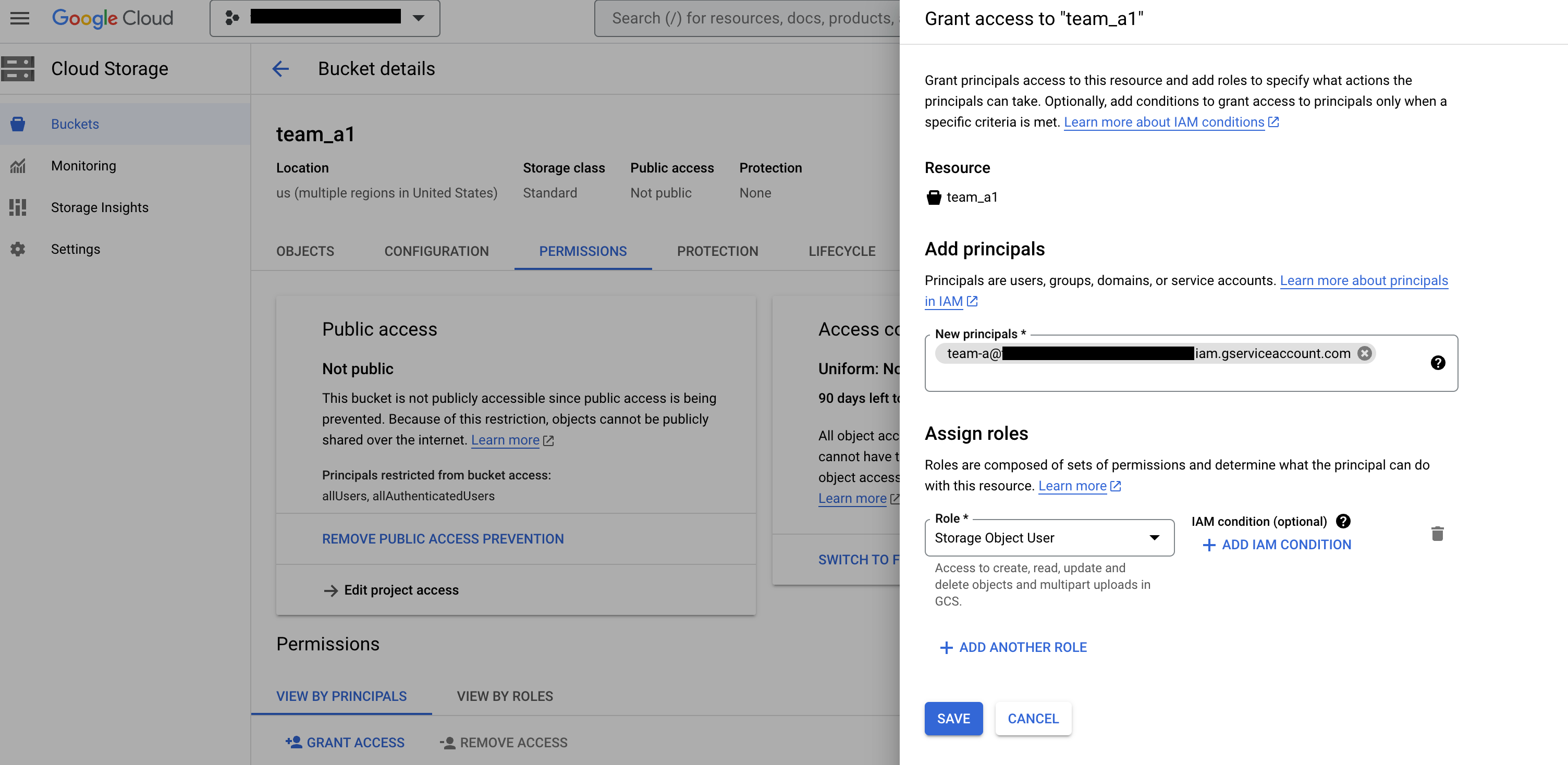
Figure 2: On the Cloud Storage Buckets page, add the team as a principal and assign the Storage Object User role.
Create the Cloud Storage connection in the respective namespaces
Create Cloud Storage connection in each team's namespace:
In the Google Cloud console, go to the Cloud Data Fusion Instances page and open an instance in the Cloud Data Fusion web interface.
Click System admin > Configuration > Namespaces.
Click the namespace you want to use—for example, the namespace for Team A.
Click the Connections tab, and then click Add connection.
Select GCS and configure the connection.
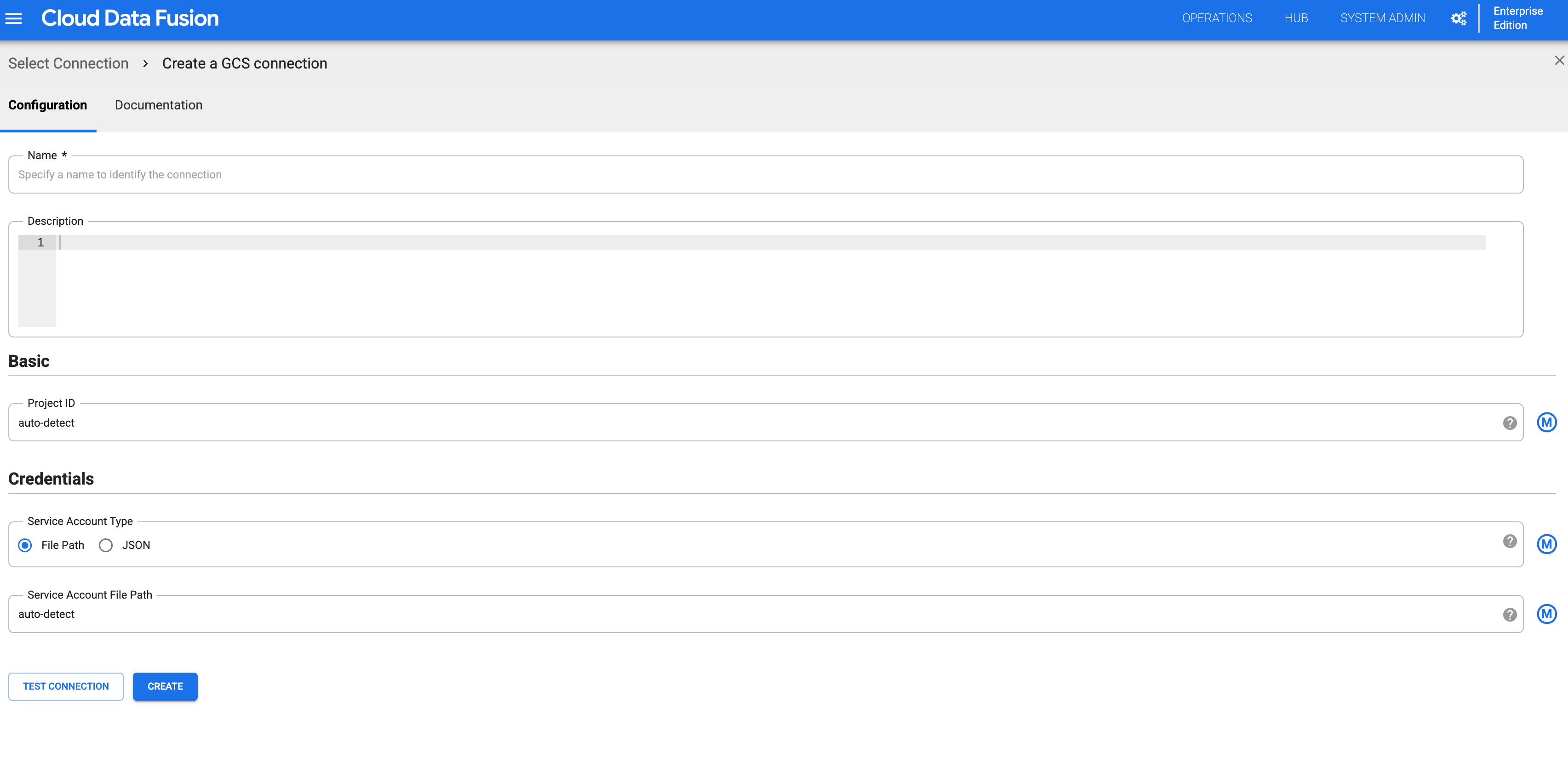
Figure 3: Configure the Cloud Storage connection for the namespace. Create a Cloud Storage connection for every namespace by repeating the preceding steps. Each team can then interact with an isolated copy of that resource for their design time operations.
Validate design time isolation for each namespace
Team A can validate the isolation at design by accessing Cloud Storage buckets in their respective namespaces:
In the Google Cloud console, go to the Cloud Data Fusion Instances page and open an instance in the Cloud Data Fusion web interface.
Click System admin > Configuration > Namespaces.
Select a namespace—for example the Team A namespace,
team_A.Click Menu > Wrangler.
Click GCS.
In the bucket list, click the
team_a1bucket.You can view the list of buckets because the Team A namespace has
storage.buckets.listpermission.When you click the bucket, you can view its contents because the Team A namespace has the Storage Object Viewer role.
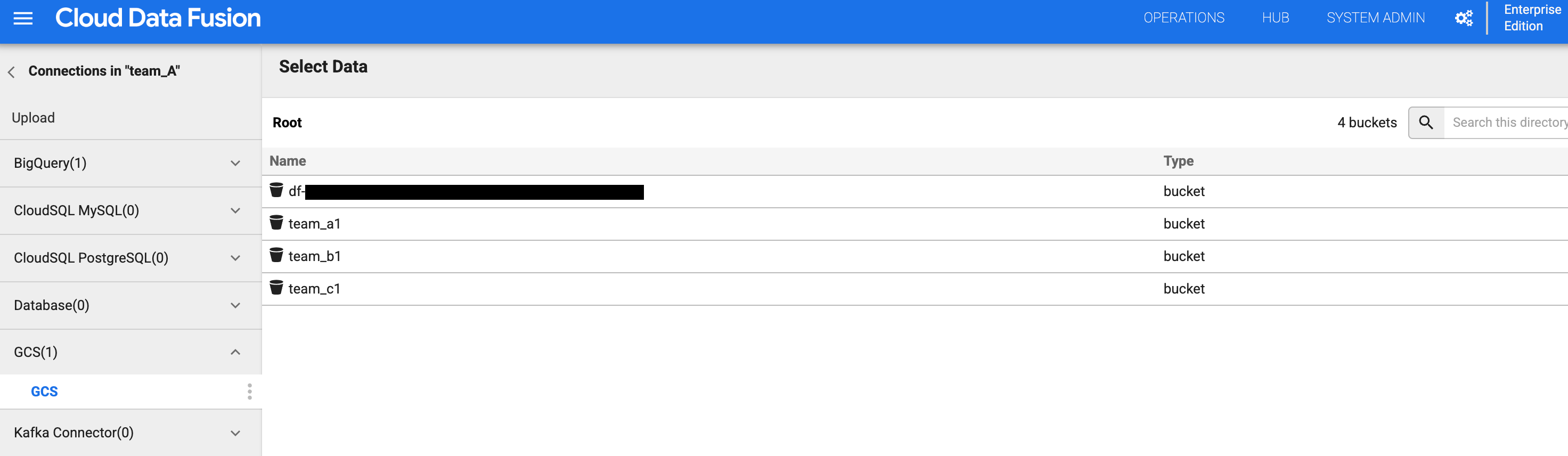
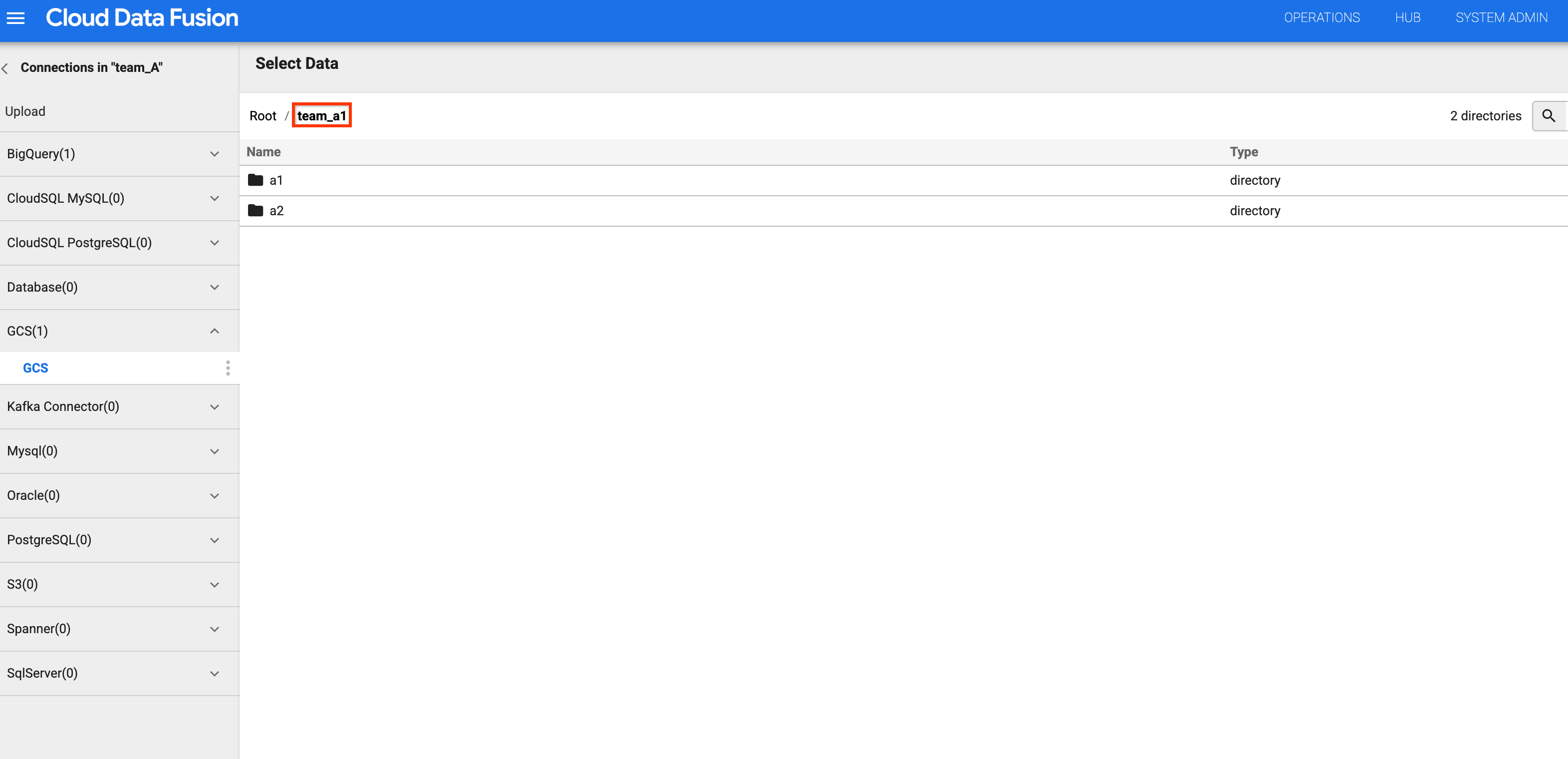
Figures 4 and 5: Check that Team A can access the appropriate storage bucket. Go back to the bucket list and click the
team_b1orteam_c1bucket. The access is restricted, as you isolated this design time resource for Team A using its namespace service account.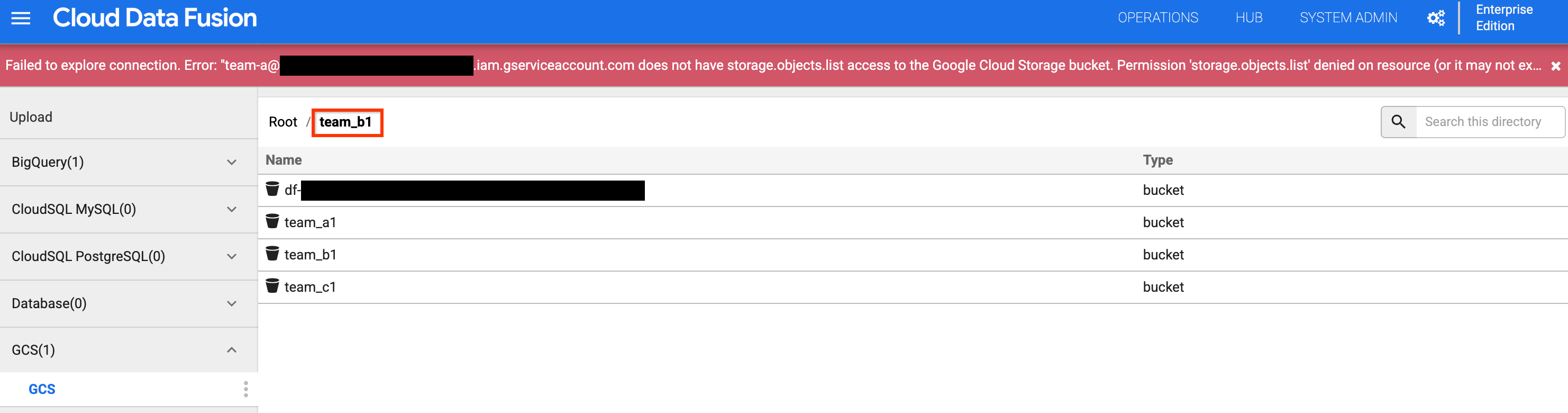
Figure 6: Check that Team A cannot access Team B and C storage buckets.
What's next
- Learn more about security features in Cloud Data Fusion.