This tutorial teaches you how to use the
TRANSFORM clause
of the CREATE MODEL statement to perform feature engineering at the same time
that you create and train a model. Using the TRANSFORM clause, you
can specify one or more preprocessing
functions to transform the input data you use to train the model. The
preprocessing that you apply to the model is automatically applied when you use
the model with the
ML.EVALUATE
and
ML.PREDICT
functions.
This tutorial uses the public
bigquery-public-data.ml_datasets.penguin dataset.
Objectives
This tutorial guides you through completing the following tasks:
- Creating a linear regression model to predict service call type by using the
CREATE MODELstatement. Within theCREATE MODELstatement, use theML.QUANTILE_BUCKETIZEandML.FEATURE_CROSSfunctions to preprocess data. - Evaluating the model by using the
ML.EVALUATEfunction. - Getting predictions from the model by using the
ML.PREDICTfunction.
Costs
This tutorial uses billable components of Google Cloud, including:
- BigQuery
- BigQuery ML
For more information about BigQuery costs, see the BigQuery pricing page.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery is automatically enabled in new projects.
To activate BigQuery in a pre-existing project, go to
Enable the BigQuery API.
Create a dataset
Create a BigQuery dataset to store your ML model.
Console
In the Google Cloud console, go to the BigQuery page.
In the Explorer pane, click your project name.
Click View actions > Create dataset.
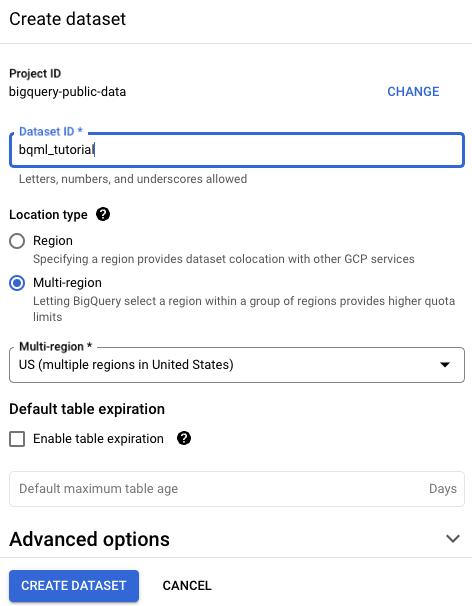
On the Create dataset page, do the following:
For Dataset ID, enter
bqml_tutorial.For Location type, select Multi-region, and then select US (multiple regions in United States).
The public datasets are stored in the
USmulti-region. For simplicity, store your dataset in the same location.- Leave the remaining default settings as they are, and click Create dataset.
bq
To create a new dataset, use the
bq mk command
with the --location flag. For a full list of possible parameters, see the
bq mk --dataset command
reference.
Create a dataset named
bqml_tutorialwith the data location set toUSand a description ofBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Instead of using the
--datasetflag, the command uses the-dshortcut. If you omit-dand--dataset, the command defaults to creating a dataset.Confirm that the dataset was created:
bq ls
API
Call the datasets.insert
method with a defined dataset resource.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Create the model
Create a linear regression model to predict penguin weight and train it on
the penguins sample table.
The OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g'])
clause indicates that you are creating a
linear regression
model. A linear regression model generates a
continuous value from a linear combination of input features. The
body_mass_g column is the input label column. For linear regression models,
the label column must be real valued (that is, the column values must be
real numbers).
This query's TRANSFORM clause uses the following columns from the SELECT
statement:
body_mass_g: Used in training without any change.culmen_depth_mm: Used in training without any change.flipper_length_mm: Used in training without any change.bucketized_culmen_length: Generated fromculmen_length_mmby bucketizingculmen_length_mmbased on quantiles using theML.QUANTILE_BUCKETIZE()analytic function.culmen_length_mm: The originalculmen_length_mmvalue, cast to aSTRINGvalue and used in training.species_sex: Generated from crossingspeciesandsexusing theML.FEATURE_CROSSfunction.
You don't need to use all of the columns from the training table
in theTRANSFORM clause.
The WHERE clause—WHERE body_mass_g IS NOT NULL AND RAND() < 0.2—
excludes rows where the penguins weight is NULL, and uses the RAND function
to draw a random sample of the data.
Follow these steps to create the model:
In the Google Cloud console, go to the BigQuery page.
In the query editor, paste in the following query and click Run:
CREATE OR REPLACE MODEL `bqml_tutorial.penguin_transform` TRANSFORM( body_mass_g, culmen_depth_mm, flipper_length_mm, ML.QUANTILE_BUCKETIZE(culmen_length_mm, 10) OVER () AS bucketized_culmen_length, CAST(culmen_length_mm AS string) AS culmen_length_mm, ML.FEATURE_CROSS(STRUCT(species, sex)) AS species_sex) OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL AND RAND() < 0.2;
The query takes about 15 minutes to complete, after which the
penguin_transformmodel appears in the Explorer pane. Because the query uses aCREATE MODELstatement to create a model, you don't see query results.
Evaluate the model
Evaluate the performance of the model by using the ML.EVALUATE function.
The ML.EVALUATE function evaluates the predicted penguin weights returned by
the model against the actual penguin weights from the training data.
This query's nested SELECT statement and FROM clause are the same as those
in the CREATE MODEL query. Because you used the TRANSFORM clause when
creating the model, you don't need to specify the columns and transformations
again in the ML.EVALUATE function. The function automatically retrieves
them from the model.
Follow these steps to evaluate the model:
In the Google Cloud console, go to the BigQuery page.
In the query editor, paste in the following query and click Run:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.penguin_transform`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL ));
The results should look similar to the following:
+---------------------+--------------------+------------------------+-----------------------+--------------------+--------------------+ | mean_absolute_error | mean_squared_error | mean_squared_log_error | median_absolute_error | r2_score | explained_variance | +---------------------+--------------------+------------------------+-----------------------+--------------------+--------------------+ | 64.21134350607677 | 13016.433317859564 | 7.140935762696211E-4 | 15.31788461553515 | 0.9813042531507734 | 0.9813186268757634 | +---------------------+--------------------+------------------------+-----------------------+--------------------+--------------------+
An important metric in the evaluation results is the R2 score. The R2 score is a statistical measure that determines if the linear regression predictions approximate the actual data. A value of
0indicates that the model explains none of the variability of the response data around the mean. A value of1indicates that the model explains all the variability of the response data around the mean.For more information about the
ML.EVALUATEfunction output, see Regression models.You can also call
ML.EVALUATEwithout providing the input data. It will use the evaluation metrics calculated during training.
Use the model to predict penguin weight
Use the model with the ML.PREDICT function to predict the weight of male
penguins.
The ML.PREDICT function outputs the predicted value in the
predicted_label_column_name column, in this case
predicted_body_mass_g.
When you use the ML.PREDICT function, you don't have to pass in all of the
columns used in model training. Only the columns that you used in the
TRANSFORM clause are required. Similar to ML.EVALUATE, the ML.PREDICT
function automatically retrieves the TRANSFORM columns and transformations
from the model.
Follow these steps to get predictions from the model:
In the Google Cloud console, go to the BigQuery page.
In the query editor, paste in the following query and click Run:
SELECT predicted_body_mass_g FROM ML.PREDICT( MODEL `bqml_tutorial.penguin_transform`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE sex = 'MALE' ));
The results should look similar to the following:
+-----------------------+ | predicted_body_mass_g | +-----------------------+ | 2810.2868541725757 | +-----------------------+ | 3813.6574220842676 | +-----------------------+ | 4098.844698262214 | +-----------------------+ | 4256.587135004173 | +-----------------------+ | 3008.393497302691 | +-----------------------+ | ... | +-----------------------+
Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
- You can delete the project you created.
- Or you can keep the project and delete the dataset.
Delete your dataset
Deleting your project removes all datasets and all tables in the project. If you prefer to reuse the project, you can delete the dataset you created in this tutorial:
If necessary, open the BigQuery page in the Google Cloud console.
In the navigation panel, click the bqml_tutorial dataset you created.
On the right side of the window, click Delete dataset. This action deletes the dataset, the table, and all the data.
In the Delete dataset dialog box, confirm the delete command by typing the name of your dataset (
bqml_tutorial) and then click Delete.
Delete your project
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
What's next
- To learn more about machine learning, see the Machine learning crash course.
- For an overview of BigQuery ML, see Introduction to BigQuery ML.
- To learn more about the Google Cloud console, see Using the Google Cloud console.