Organizing BigQuery resources
Like other Google Cloud services, BigQuery resources are organized in a hierarchy. You can use this hierarchy to manage aspects of your BigQuery workloads such as permissions, quotas, slot reservations, and billing.
Resource hierarchy
BigQuery inherits the Google Cloud resource hierarchy and adds an additional grouping mechanism called datasets, which are specific to BigQuery. This section describes the elements of this hierarchy.
Datasets
Datasets are logical containers that are used to organize and control access to your BigQuery resources. Datasets are similar to schemas in other database systems.
Most BigQuery resources that you create — including tables, views, functions, and procedures — are created inside a dataset. Connections and jobs are exceptions; these are associated with projects rather than datasets.
A dataset has a location. When you create a table, the table data is stored in the location of the dataset. Before you create tables for production data, think about your location requirements. You cannot change the location of a dataset after it is created.
Projects
Every dataset is associated with a project. To use Google Cloud, you must create at least one project. Projects form the basis for creating, enabling, and using all Google Cloud services. For more information, see Resource hierarchy. A project can hold multiple datasets, and datasets with different locations can exist in the same project.
When you perform operations on your BigQuery data, such as running a query or ingesting data into a table, you create a job. A job is always associated with a project, but it doesn't have to run in the same project that contains the data. In fact, a job might reference tables from datasets in multiple projects. A query job, load job, or export job always runs in the same location as the tables that it references.
Each project has a Cloud Billing account attached to it. The costs accrued to a project are billed to that account. If you use on-demand pricing, your queries are billed to the project that runs the query. If you use capacity-based pricing, your slot reservations are billed to the administration project used to purchase the slots. Storage is charged to the project where the dataset resides.
Folders
Folders are an additional grouping mechanism above projects. Projects and folders inside a folder automatically inherit the access policies of their parent folder. Folders can be used to model different legal entities, departments, and teams within a company.
Organizations
The Organization resource represents an organization (for example, a company) and is the root node in the Google Cloud resource hierarchy.
You don't need an Organization resource to get started using BigQuery, but we recommend creating one. Using an Organization resource allows administrators to centrally control your BigQuery resources, rather than individual users controlling the resources they create.
The following diagram shows an example of the resource hierarchy. In this example, the organization has a project inside a folder. The project is associated with a billing account, and it contains three datasets.
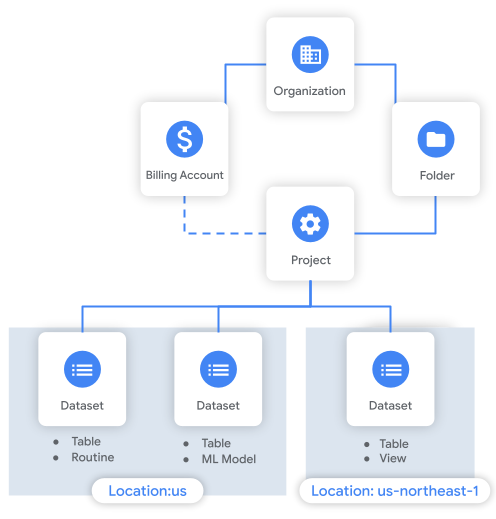
Considerations
When choosing how to organize your BigQuery resources, consider the following points:
- Quotas. Many BigQuery quotas are applied at the project level. A few apply at the dataset level. Project-level quotas that involve compute resources, such as queries and load jobs, are counted against the project that creates the job, rather than the storage project.
- Billing. If you want different departments in your organization to use different Cloud Billing accounts, then create different projects for each team. Create the Cloud Billing accounts at the organization level and associate the projects to them.
- Slot reservations. Reserved slots are scoped to the Organization resource. After you purchase reserved slot capacity, you can assign a pool of slots to any project or folder within the organization, or assign slots to the entire Organization resource. Projects inherit slot reservations from their parent folder or Organization. Reserved slots are associated with an administration project, which is used to manage the slots. For more information, see Workload management using Reservations.
Permissions. Consider how your permissions hierarchy affects the people in your organization who need to access the data. For example, if you want to give an entire team access to specific data, you might store that data in a single project to simplify access management.
Tables and other entities inherit the permissions of their parent dataset. Datasets inherit permissions from their parent entities in the resource hierarchy (projects, folders, organizations). To perform an operation on a resource, a user needs both the relevant permissions on the resource, and also permission to create a BigQuery job. The permission to create a job is associated with the project that is used for that job.
Patterns
This section presents two common patterns for organizing BigQuery resources.
Central data lake, department data marts. The organization creates a unified storage project to hold its raw data. Departments within the organization create their own data mart projects for analysis.
Department data lakes, central data warehouse. Each department creates and manages its own storage project to hold that department's raw data. The organization then creates a central data warehouse project for analysis.
There are advantages and tradeoffs to each approach. Many organizations combine elements of both patterns.
Central data lake, department data marts
In this pattern, you create a unified storage project to hold your organization's raw data. Your data ingestion pipeline can also run in this project. The unified storage project acts as a data lake for your organization.
Each department has its own dedicated project, which it uses to query the data, save query results, and create views. These department-level projects act as data marts. They are associated with the department's billing account.
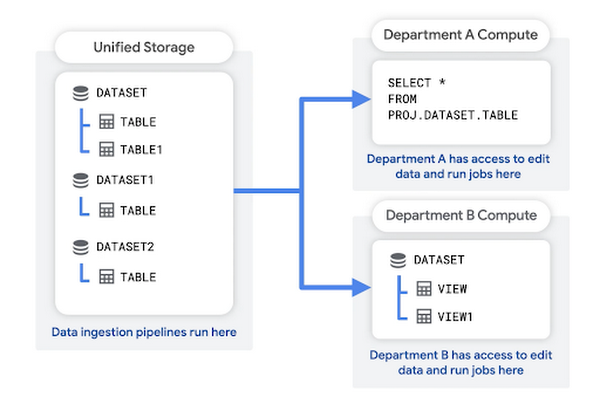
Advantages of this structure include:
- A centralized data engineering team can manage the ingestion pipeline in a single place.
- The raw data is isolated from the department-level projects.
- With on-demand pricing, billing for running queries is charged to the department that runs the query.
- With capacity-based pricing, you can assign slots to each department based on their projected compute requirements.
- Each department is isolated from the others in terms of project-level quotas.
When using this structure, the following permissions are typical:
- The central data engineering team is granted the BigQuery Data Editor and BigQuery Job User roles for the storage project. These allow them to ingest and edit data in the storage project.
- Department analysts are granted the BigQuery Data Viewer role for specific datasets in the central data lake project. This allows them to query the data, but not to update or delete the raw data.
- Department analysts are also granted the BigQuery Data Editor role and Job User role for their department's data mart project. This allows them to create and update tables in their project and run query jobs, in order to transform and aggregate the data for department-specific usage.
For more information, see Basic roles and permissions.
Department data lakes, central data warehouse
In this pattern, each department creates and manages its own storage project, which holds that department's raw data. A central data warehouse project stores aggregations or transformations of the raw data.
Analysts can query and read the aggregated data from the data warehouse project. The data warehouse project also provides an access layer for business intelligence (BI) tools.
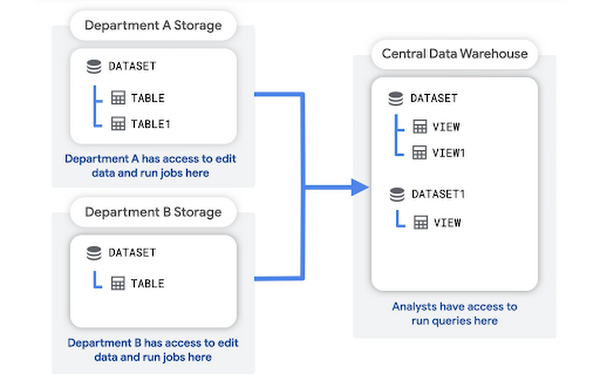
Advantages of this structure include:
- It is simpler to manage data access at the department level, by using separate projects for each department.
- A central analytics team has a single project for running analytics jobs, which makes it easier to monitor queries.
- Users can access data from a centralized BI tool, which is kept isolated from the raw data.
- Slots can be assigned to the data warehouse project to handle all queries from analysts and external tools.
When using this structure, the following permissions are typical:
- Data engineers are granted BigQuery Data Editor and BigQuery Job User roles in their department's data mart. These roles allow them to ingest and transform data into their data mart.
- Analysts are granted BigQuery Data Editor and BigQuery Job User roles in the data warehouse project. These roles allow them to create aggregate views in the data warehouse and run query jobs.
- Service accounts that connect BigQuery to BI tools are granted the BigQuery Data Viewer role for specific datasets, which can hold either raw data from the data lake or transformed data in the data warehouse project.
For more information, see Basic roles and permissions.
You can also use security features such as authorized views and authorized user-defined functions (UDFs) to make aggregated data available to certain users without granting them permission to see the raw data in the data mart projects.
This project structure can result in many concurrent queries in the data warehouse project. As a result, you might hit the concurrent query limit. If you adopt this structure, consider raising this quota limit for the project. Also consider using capacity-based billing, so that you can purchase a pool of slots to run the queries.