This page applies to Apigee and Apigee hybrid.
View
Apigee Edge documentation.

When you see an anomaly in the Operations Anomalies dashboard, you can investigate it further in the API Monitoring dashboards. The dashboards display graphs and tables of recent API data, which provide highly specific information about what was occurring in the API at the time of the anomaly.
The following sections present examples that illustrate how to investigate anomalies in the dashboards.
Example: fault code anomaly
Suppose are looking at the Operations Anomalies dashboard, and you notice the anomaly shown below:

To view the details of the anomaly, click Investigate in the Summary column. This displays the API Monitoring Investigate dashboard, as shown below.
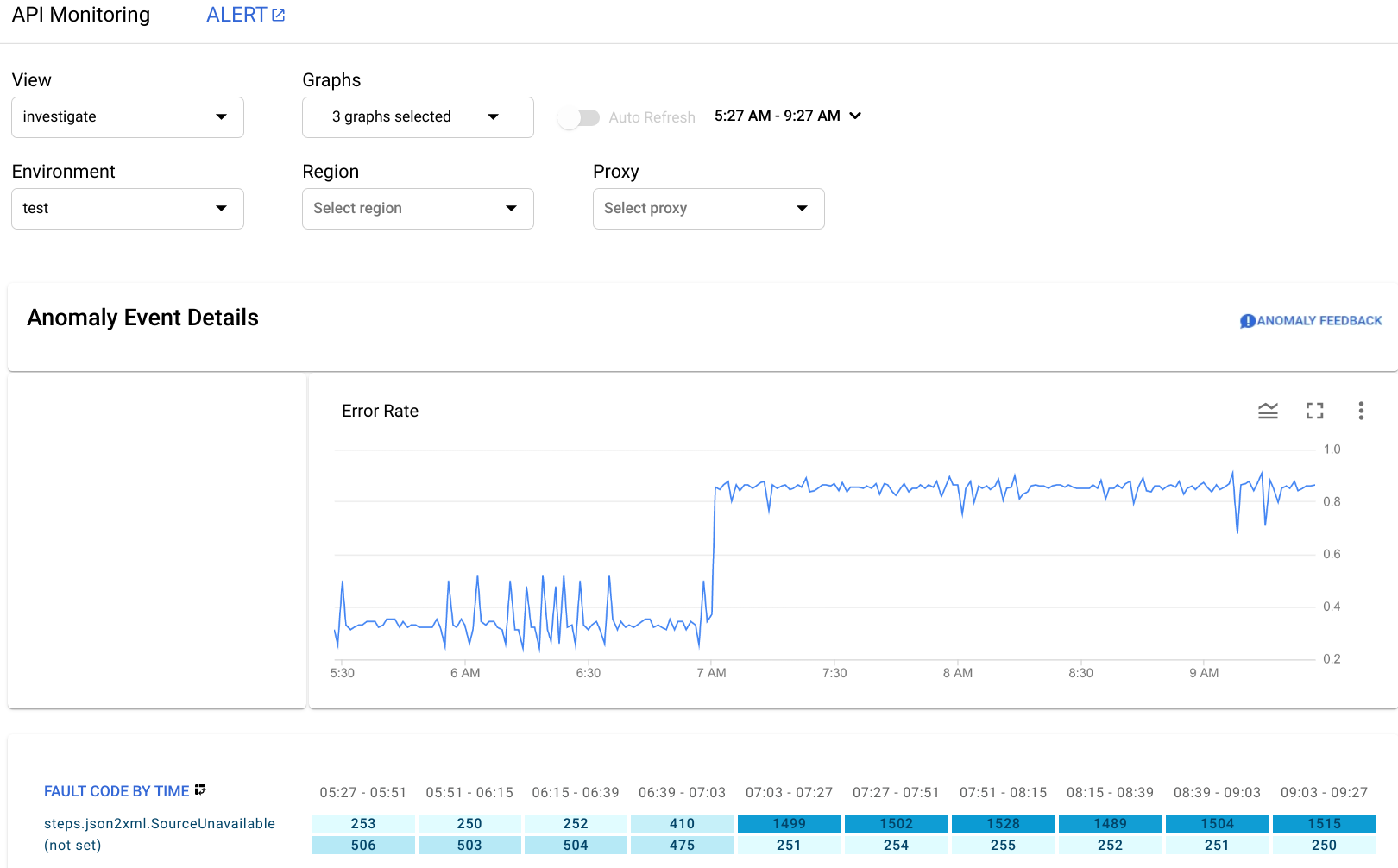
The Anomaly Event Details pane displays an error rate timeline. The graph shows that the anomaly occurred after 07:00 AM, when the error rate jumped from less than 0.4 to more than 0.8.
The error rate in the timeline graph includes errors for all fault codes. To see a breakdown of errors for different fault codes, look at the Fault Code by Time graph displayed below the timeline.
Note: If the Fault Code by Time graph
isn't currently displayed, select Fault Code in the Graphs menu to show it:
The circled column of the Fault Code by Time graph corresponds to the time interval containing the time of the anomaly.
Note: A small difference between the data displayed in the graph and the reported time of the anomaly is normal.

You observe that in the
interval 07:03 - 07:27, there were 1499 responses with fault code
steps.json2xml.SourceUnavailable (an error code
that is returned when a JSON to XML policy message source is unavailable).
This is the fault code that triggered the anomaly.
By contrast, over the preceding four
intervals the average number of responses with that fault code was about 291, so the jump to 1499
was certainly an unusual event.
For more information about the SourceUnavailable error message, see
JSON to XML policy runtime error troubleshooting.
At this point, there are a couple of ways to continue investigating the cause of the anomaly:
Drill down on the fault code data at the time of the anomaly by clicking the cell for the anomaly in the Fault Code by Time graph.
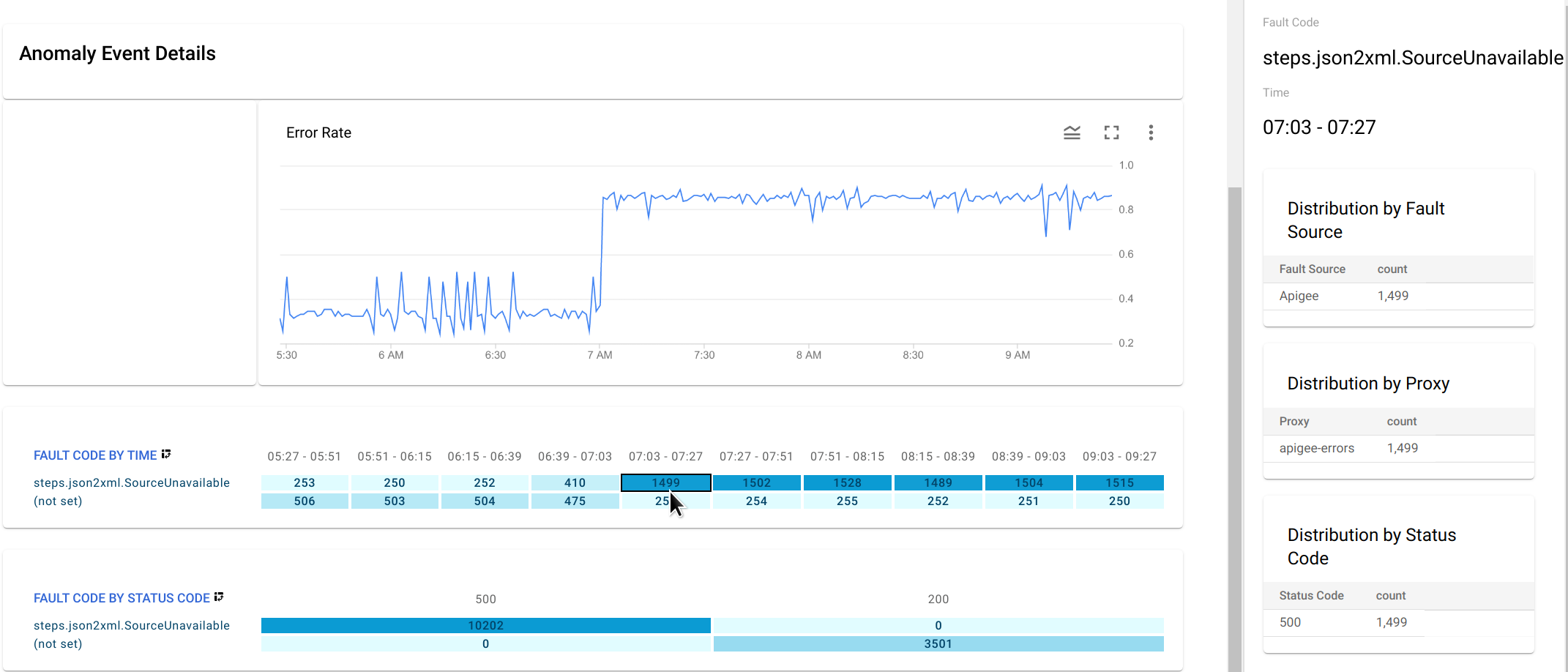
This displays distribution tables for
steps.json2xml.SourceUnavailableby fault source, proxy, and status code in the right-hand pane.In this example, the tables don't provide any additional information because all the fault codes arise from the same fault source, proxy, and status code. But in other situations, the distribution tables can point you to the location and cause of the anomaly.
- Create an alert for the anomaly and set up a notification. After you have done this, AAPI Ops will send you a message whenever a similar event occurs in the future.